Salman Khan, Sumaiya Noor, Tahir Javed, Afshan Naseem, Fahad Aslam, Salman A AlQahtani, Nijad Ahmad
{"title":"XGBoost-enhanced ensemble model using discriminative hybrid features for the prediction of sumoylation sites.","authors":"Salman Khan, Sumaiya Noor, Tahir Javed, Afshan Naseem, Fahad Aslam, Salman A AlQahtani, Nijad Ahmad","doi":"10.1186/s13040-024-00415-8","DOIUrl":null,"url":null,"abstract":"<p><p>Posttranslational modifications (PTMs) are essential for regulating protein localization and stability, significantly affecting gene expression, biological functions, and genome replication. Among these, sumoylation a PTM that attaches a chemical group to protein sequences-plays a critical role in protein function. Identifying sumoylation sites is particularly important due to their links to Parkinson's and Alzheimer's. This study introduces XGBoost-Sumo, a robust model to predict sumoylation sites by integrating protein structure and sequence data. The model utilizes a transformer-based attention mechanism to encode peptides and extract evolutionary features through the PsePSSM-DWT approach. By fusing word embeddings with evolutionary descriptors, it applies the SHapley Additive exPlanations (SHAP) algorithm for optimal feature selection and uses eXtreme Gradient Boosting (XGBoost) for classification. XGBoost-Sumo achieved an impressive accuracy of 99.68% on benchmark datasets using 10-fold cross-validation and 96.08% on independent samples. This marks a significant improvement, outperforming existing models by 10.31% on training data and 2.74% on independent tests. The model's reliability and high performance make it a valuable resource for researchers, with strong potential for applications in pharmaceutical development.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"12"},"PeriodicalIF":6.1000,"publicationDate":"2025-02-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11792219/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00415-8","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
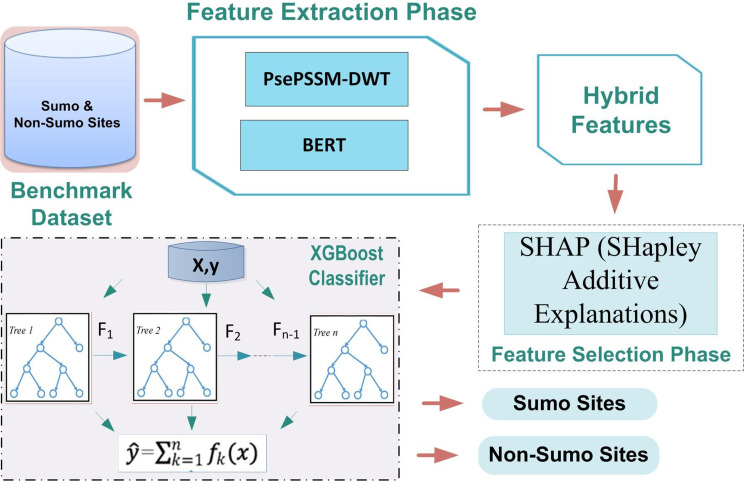
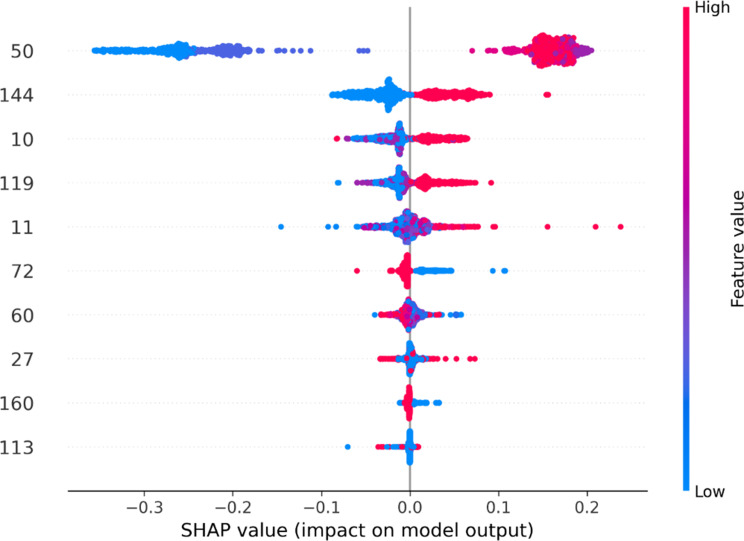
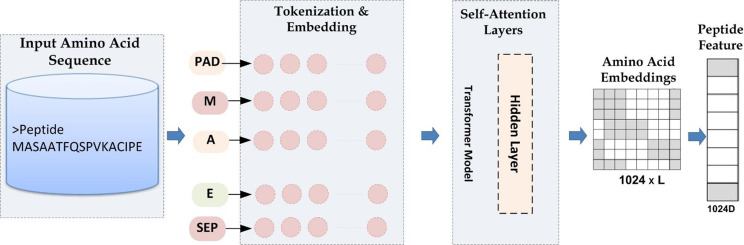
Posttranslational modifications (PTMs) are essential for regulating protein localization and stability, significantly affecting gene expression, biological functions, and genome replication. Among these, sumoylation a PTM that attaches a chemical group to protein sequences-plays a critical role in protein function. Identifying sumoylation sites is particularly important due to their links to Parkinson's and Alzheimer's. This study introduces XGBoost-Sumo, a robust model to predict sumoylation sites by integrating protein structure and sequence data. The model utilizes a transformer-based attention mechanism to encode peptides and extract evolutionary features through the PsePSSM-DWT approach. By fusing word embeddings with evolutionary descriptors, it applies the SHapley Additive exPlanations (SHAP) algorithm for optimal feature selection and uses eXtreme Gradient Boosting (XGBoost) for classification. XGBoost-Sumo achieved an impressive accuracy of 99.68% on benchmark datasets using 10-fold cross-validation and 96.08% on independent samples. This marks a significant improvement, outperforming existing models by 10.31% on training data and 2.74% on independent tests. The model's reliability and high performance make it a valuable resource for researchers, with strong potential for applications in pharmaceutical development.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


