Analyzing large text data for vocabulary profiling in corpus-based studies of academic discourse
IF 1.6
Q2 MULTIDISCIPLINARY SCIENCES
引用次数: 0
Abstract
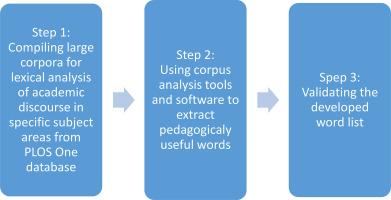
This article introduces a protocol designed to analyze large corpora for vocabulary profiling, aimed at enhancing corpus-based studies of academic discourse. Given the complexity and volume of data typical in academic fields, this protocol integrates advanced corpus compilation techniques with lexical analysis tools to effectively identify and categorize vocabulary suitable for academic use. The study details the systematic process of compiling a large corpus of academic texts, and describes the adaptations made to corpus linguistics tools to handle and analyze a corpus with 278 million running words efficiently. Validation of the mid-frequency word list demonstrated its strong relevance to chemistry, with 6.4% coverage in chemistry research articles and 2.5–3% coverage in related disciplines like biology and life sciences. However, the coverage was much lower in general corpora, highlighting its specialized nature. This methodology not only provides a framework for academic vocabulary profiling but also offers scalable solutions for educators and researchers dealing with extensive text datasets. The findings contribute to advancing vocabulary research in chemistry and related fields, offering practical applications for improving educational resources and designing more effective curricula for academic English. The resulting vocabulary lists have significant implications for the design of curricula and educational resources, aiming to improve both the precision and effectiveness of language instruction in specialized academic settings.
- •Developed a scalable protocol for analyzing large text data for vocabulary profiling.
- •Applied advanced lexical analysis to a 278-million-word academic corpus.
- •The mid-frequency vocabulary list produced offers pedagogical value in academic discourse.
在基于语料库的学术语篇研究中,对大文本数据进行词汇分析。
本文介绍了一个大型语料库词汇分析协议,旨在加强基于语料库的学术语篇研究。鉴于学术领域典型的数据复杂性和数据量,该协议将先进的语料库编译技术与词汇分析工具相结合,有效地识别和分类适合学术使用的词汇。该研究详细介绍了编制大型学术文本语料库的系统过程,并描述了对语料库语言学工具的调整,以有效地处理和分析2.78亿运行词的语料库。中频词表的验证表明其与化学的相关性很强,化学研究文章的覆盖率为6.4%,生物和生命科学等相关学科的覆盖率为2.5-3%。但是,一般语料库的覆盖率要低得多,突出了其专业性。这种方法不仅为学术词汇分析提供了一个框架,而且为教育工作者和研究人员处理广泛的文本数据集提供了可扩展的解决方案。研究结果有助于推进化学及相关领域的词汇研究,为改进教育资源和设计更有效的学术英语课程提供实际应用。由此产生的词汇表对课程和教育资源的设计具有重要意义,旨在提高专业学术环境下语言教学的准确性和有效性。•开发了一个可扩展的协议,用于分析词汇分析的大型文本数据。•应用先进的词汇分析2.78亿字的学术语料库。•产生的中频词汇表在学术话语中具有教学价值。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

MethodsX
Health Professions-Medical Laboratory Technology
CiteScore
3.60
自引率
5.30%
发文量
314
审稿时长
7 weeks
期刊介绍:
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


