Vaakesan Sundrelingam, Shireen Parimoo, Frances Pogacar, Radha Koppula, Saeha Shin, Chloe Pou-Prom, Surain B Roberts, Amol A Verma, Fahad Razak
{"title":"pyDeid: an improved, fast, flexible, and generalizable rule-based approach for deidentification of free-text medical records.","authors":"Vaakesan Sundrelingam, Shireen Parimoo, Frances Pogacar, Radha Koppula, Saeha Shin, Chloe Pou-Prom, Surain B Roberts, Amol A Verma, Fahad Razak","doi":"10.1093/jamiaopen/ooae152","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Deidentification of personally identifiable information in free-text clinical data is fundamental to making these data broadly available for research. However, there exist gaps in the deidentification landscape with regard to the functionality and flexibility of extant tools, as well as suboptimal tradeoffs between deidentification accuracy and speed. To address these gaps and tradeoffs, we develop a new Python-based deidentification software, pyDeid.</p><p><strong>Materials and methods: </strong>pyDeid uses a combination of regular expression-based rules, fixed exclusion lists and inclusion lists to deidentify free-text data. Additional configurations of pyDeid include optional named entity recognition and custom name lists. We measure its deidentification performance and speed on 700 admission notes from a Canadian hospital, the publicly available n2c2 benchmark dataset of American discharge notes, as well as a synthetic dataset of artificial intelligence (AI) generated admission notes. We also compare its performance with the Physionet De-identification Software and the popular open-source Philter tool.</p><p><strong>Results: </strong>Different configurations of pyDeid outperformed other tools on various metrics, with a \"best\" accuracy value of 0.988, best precision of 0.889, best recall of 0.950, and best F1 score of 0.904. All configurations of pyDeid were significantly faster than Philter and Physionet De-identification Software, with the fastest deidentification speed of 0.48 s per note.</p><p><strong>Discussion and conclusions: </strong>pyDeid allows the flexibility to prioritize between performance and speed, as well as precision and recall, while addressing some of the gaps in functionality left by other tools. pyDeid is also generalizable to domains outside of clinical data and can be further customized for specific contexts or for particular workflows.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 1","pages":"ooae152"},"PeriodicalIF":3.4000,"publicationDate":"2025-01-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11752853/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooae152","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/2/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
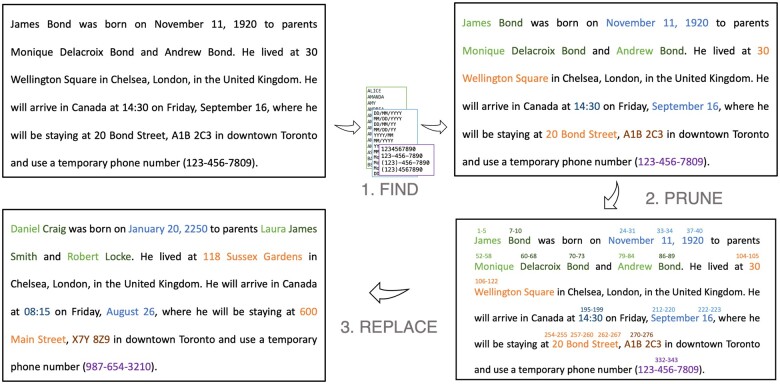
Objectives: Deidentification of personally identifiable information in free-text clinical data is fundamental to making these data broadly available for research. However, there exist gaps in the deidentification landscape with regard to the functionality and flexibility of extant tools, as well as suboptimal tradeoffs between deidentification accuracy and speed. To address these gaps and tradeoffs, we develop a new Python-based deidentification software, pyDeid.
Materials and methods: pyDeid uses a combination of regular expression-based rules, fixed exclusion lists and inclusion lists to deidentify free-text data. Additional configurations of pyDeid include optional named entity recognition and custom name lists. We measure its deidentification performance and speed on 700 admission notes from a Canadian hospital, the publicly available n2c2 benchmark dataset of American discharge notes, as well as a synthetic dataset of artificial intelligence (AI) generated admission notes. We also compare its performance with the Physionet De-identification Software and the popular open-source Philter tool.
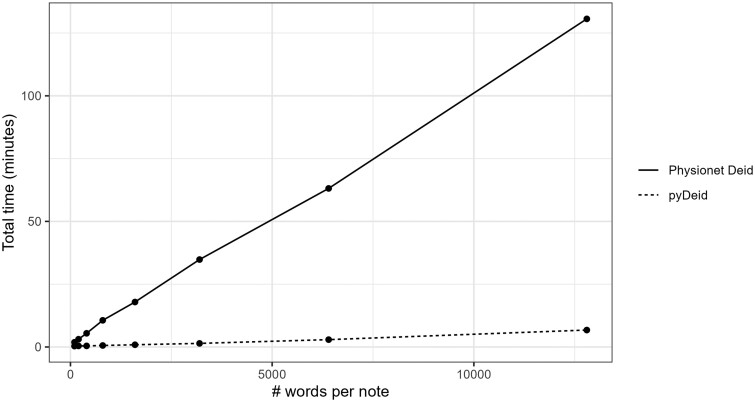
Results: Different configurations of pyDeid outperformed other tools on various metrics, with a "best" accuracy value of 0.988, best precision of 0.889, best recall of 0.950, and best F1 score of 0.904. All configurations of pyDeid were significantly faster than Philter and Physionet De-identification Software, with the fastest deidentification speed of 0.48 s per note.
Discussion and conclusions: pyDeid allows the flexibility to prioritize between performance and speed, as well as precision and recall, while addressing some of the gaps in functionality left by other tools. pyDeid is also generalizable to domains outside of clinical data and can be further customized for specific contexts or for particular workflows.
目的:在自由文本临床数据中去识别个人身份信息是使这些数据广泛用于研究的基础。然而,在现有工具的功能和灵活性以及去识别准确性和速度之间的次优权衡方面,去识别领域存在差距。为了解决这些差距和权衡,我们开发了一个新的基于python的去标识软件pyDeid。材料和方法:pyDeid使用基于正则表达式的规则、固定排除列表和包含列表的组合来去标识自由文本数据。pyDeid的其他配置包括可选的命名实体识别和自定义名称列表。我们对来自加拿大一家医院的700张住院记录、美国出院记录的公开n2c2基准数据集以及人工智能(AI)生成的住院记录的合成数据集进行了去识别性能和速度的测量。我们还将其性能与Physionet去识别软件和流行的开源Philter工具进行了比较。结果:不同配置的pyDeid在各种指标上都优于其他工具,最佳准确度值为0.988,最佳精密度为0.889,最佳召回率为0.950,最佳F1得分为0.904。pyDeid的所有配置都明显快于Philter和Physionet去识别软件,最快的去识别速度为0.48 s /音符。讨论和结论:pyDeid允许在性能和速度之间以及精度和召回之间灵活地确定优先级,同时解决了其他工具留下的一些功能差距。pyDeid还可以推广到临床数据以外的领域,并且可以针对特定上下文或特定工作流进一步定制。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


