Self-supervised pretraining in the wild imparts image acquisition robustness to medical image transformers: an application to lung cancer segmentation.
{"title":"Self-supervised pretraining in the wild imparts image acquisition robustness to medical image transformers: an application to lung cancer segmentation.","authors":"Jue Jiang, Harini Veeraraghavan","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Self-supervised learning (SSL) is an approach to pretrain models with unlabeled datasets and extract useful feature representations such that these models can be easily fine-tuned for various downstream tasks. Self-pretraining applies SSL on curated task-specific datasets without using task-specific labels. Increasing availability of public data repositories has now made it possible to utilize diverse and large, task unrelated datasets to pretrain models in the \"wild\" using SSL. However, the benefit of such wild-pretraining over self-pretraining has not been studied in the context of medical image analysis. Hence, we analyzed transformers (Swin and ViT) and a convolutional neural network created using wild- and self-pretraining trained to segment lung tumors from 3D-computed tomography (CT) scans in terms of: (a) accuracy, (b) fine-tuning epoch efficiency, and (c) robustness to image acquisition differences (contrast versus non-contrast, slice thickness, and image reconstruction kernels). We also studied feature reuse using centered kernel alignment (CKA) with the Swin networks. Our analysis with two independent testing (public N = 139; internal N = 196) datasets showed that wild-pretrained Swin models significantly outperformed self-pretrained Swin for the various imaging acquisitions. Fine-tuning epoch efficiency was higher for both wild-pretrained Swin and ViT models compared to their self-pretrained counterparts. Feature reuse close to the final encoder layers was lower than in the early layers for wild-pretrained models irrespective of the pretext tasks used in SSL. Models and code will be made available through GitHub upon manuscript acceptance.</p>","PeriodicalId":74504,"journal":{"name":"Proceedings of machine learning research","volume":"250 ","pages":"708-721"},"PeriodicalIF":0.0000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11741178/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proceedings of machine learning research","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
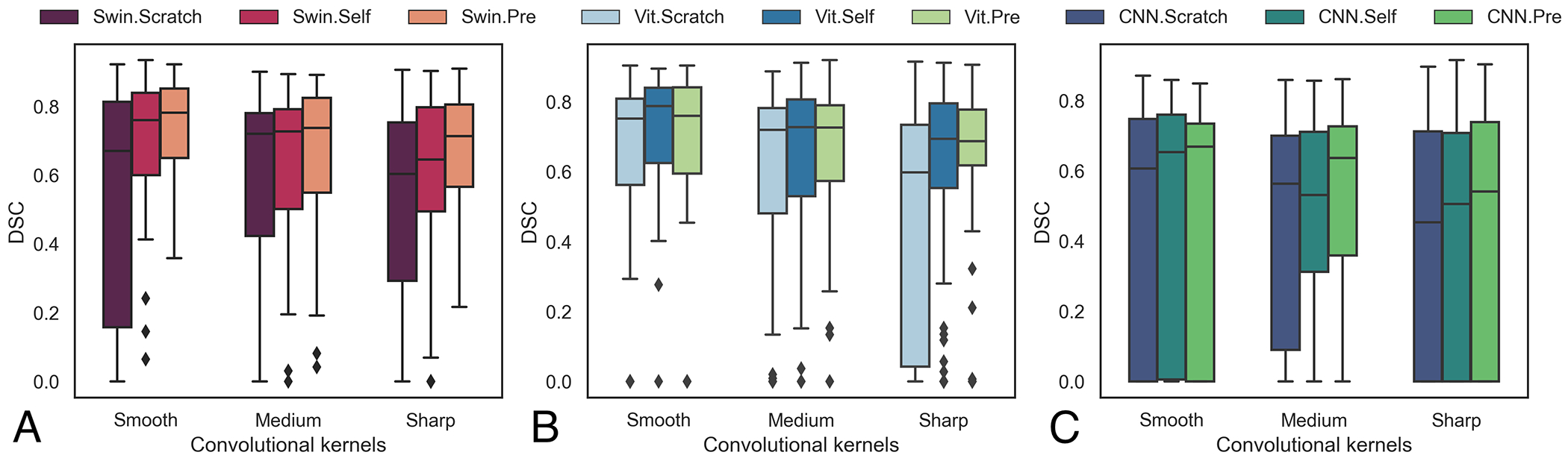
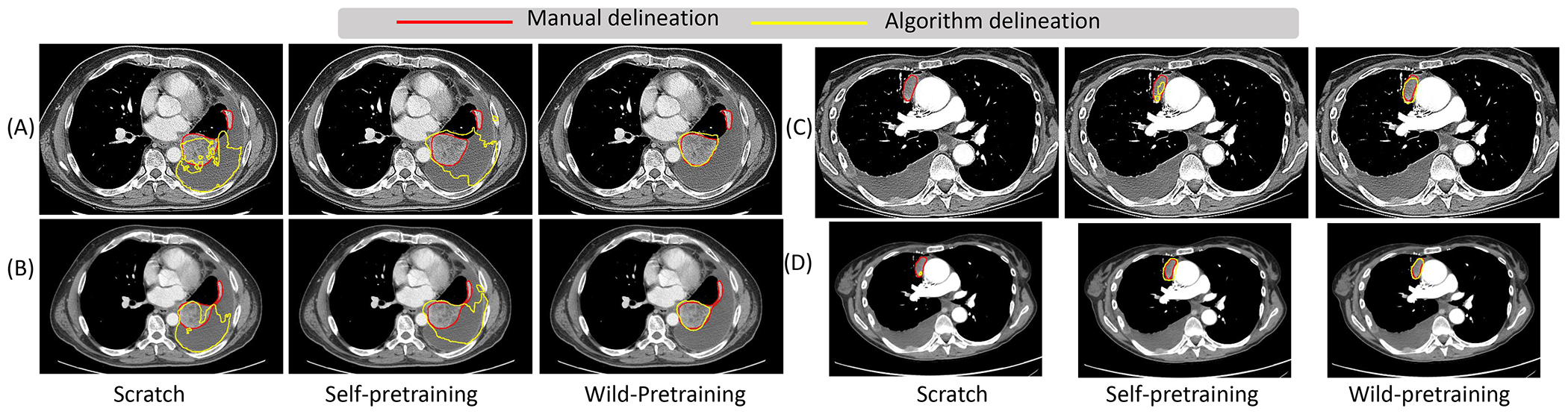
Self-supervised learning (SSL) is an approach to pretrain models with unlabeled datasets and extract useful feature representations such that these models can be easily fine-tuned for various downstream tasks. Self-pretraining applies SSL on curated task-specific datasets without using task-specific labels. Increasing availability of public data repositories has now made it possible to utilize diverse and large, task unrelated datasets to pretrain models in the "wild" using SSL. However, the benefit of such wild-pretraining over self-pretraining has not been studied in the context of medical image analysis. Hence, we analyzed transformers (Swin and ViT) and a convolutional neural network created using wild- and self-pretraining trained to segment lung tumors from 3D-computed tomography (CT) scans in terms of: (a) accuracy, (b) fine-tuning epoch efficiency, and (c) robustness to image acquisition differences (contrast versus non-contrast, slice thickness, and image reconstruction kernels). We also studied feature reuse using centered kernel alignment (CKA) with the Swin networks. Our analysis with two independent testing (public N = 139; internal N = 196) datasets showed that wild-pretrained Swin models significantly outperformed self-pretrained Swin for the various imaging acquisitions. Fine-tuning epoch efficiency was higher for both wild-pretrained Swin and ViT models compared to their self-pretrained counterparts. Feature reuse close to the final encoder layers was lower than in the early layers for wild-pretrained models irrespective of the pretext tasks used in SSL. Models and code will be made available through GitHub upon manuscript acceptance.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


