Jonathan D Schwartzman, M Kareem Shaath, Matthew S Kerr, Cody C Green, George J Haidukewych
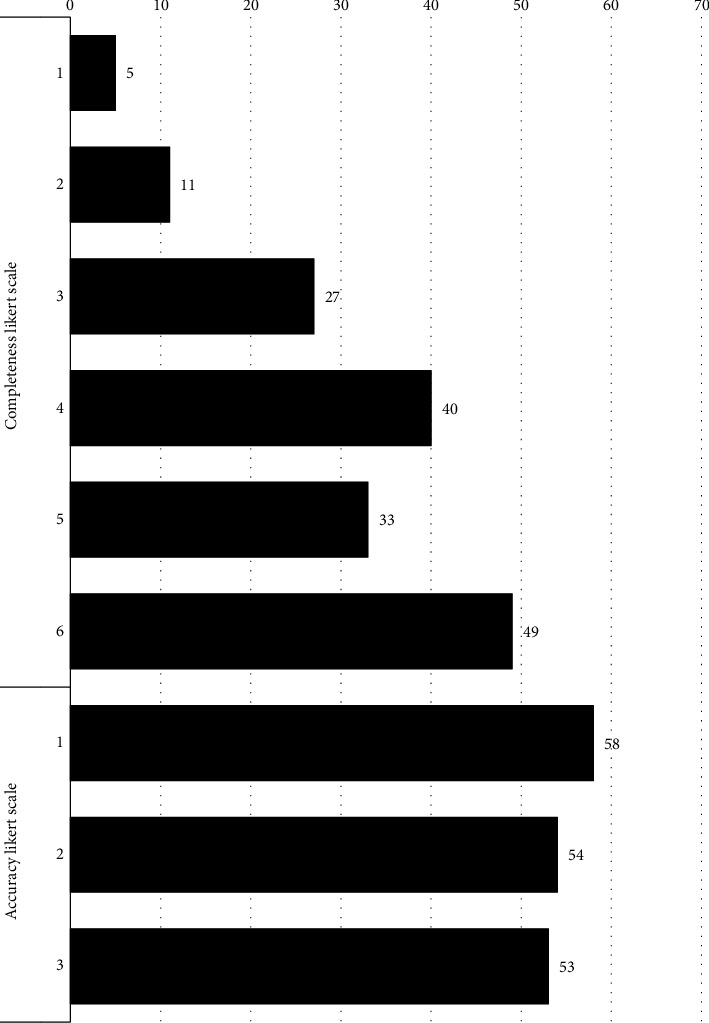
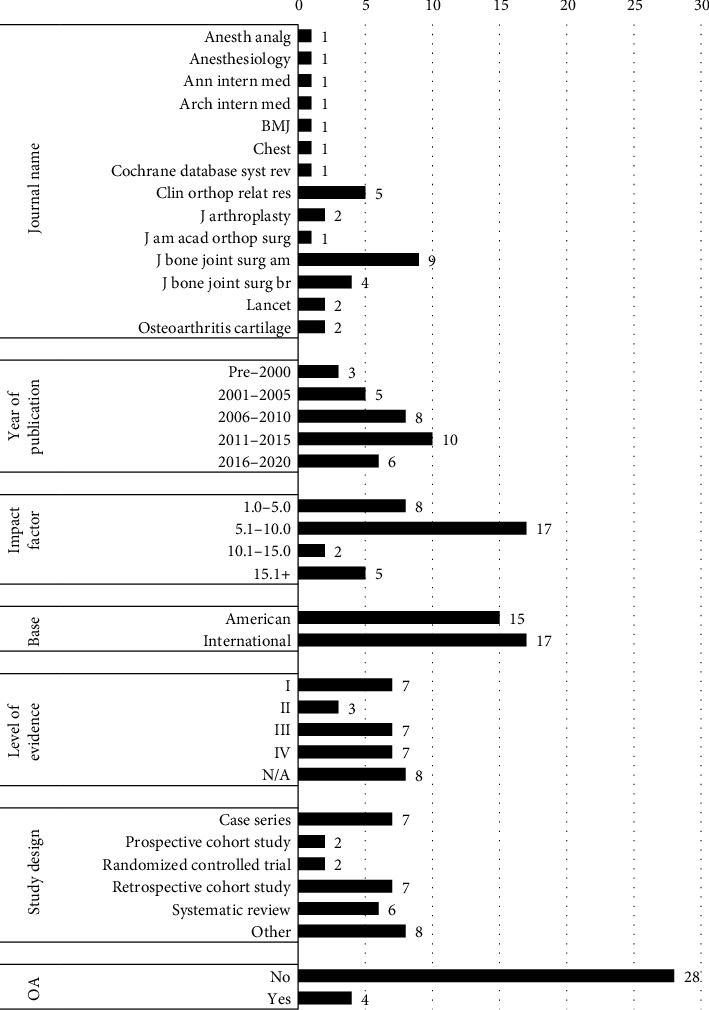
{"title":"ChatGPT is an Unreliable Source of Peer-Reviewed Information for Common Total Knee and Hip Arthroplasty Patient Questions.","authors":"Jonathan D Schwartzman, M Kareem Shaath, Matthew S Kerr, Cody C Green, George J Haidukewych","doi":"10.1155/aort/5534704","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background:</b> Advances in artificial intelligence (AI), machine learning, and publicly accessible language model tools such as ChatGPT-3.5 continue to shape the landscape of modern medicine and patient education. ChatGPT's open access (OA), instant, human-sounding interface capable of carrying discussion on myriad topics makes it a potentially useful resource for patients seeking medical advice. As it pertains to orthopedic surgery, ChatGPT may become a source to answer common preoperative questions regarding total knee arthroplasty (TKA) and total hip arthroplasty (THA). Since ChatGPT can utilize the peer-reviewed literature to source its responses, this study seeks to characterize the validity of its responses to common TKA and THA questions and characterize the peer-reviewed literature that it uses to formulate its responses. <b>Methods:</b> Preoperative TKA and THA questions were formulated by fellowship-trained adult reconstruction surgeons based on common questions posed by patients in the clinical setting. Questions were inputted into ChatGPT with the initial request of using solely the peer-reviewed literature to generate its responses. The validity of each response was rated on a Likert scale by the fellowship-trained surgeons, and the sources utilized were characterized in terms of accuracy of comparison to existing publications, publication date, study design, level of evidence, journal of publication, journal impact factor based on the clarivate analytics factor tool, journal OA status, and whether the journal is based in the United States. <b>Results:</b> A total of 109 sources were cited by ChatGPT in its answers to 17 questions regarding TKA procedures and 16 THA procedures. Thirty-nine sources (36%) were deemed accurate or able to be directly traced to an existing publication. Of these, seven (18%) were identified as duplicates, yielding a total of 32 unique sources that were identified as accurate and further characterized. The most common characteristics of these sources included dates of publication between 2011 and 2015 (10), publication in The Journal of Bone and Joint Surgery (13), journal impact factors between 5.1 and 10.0 (17), internationally based journals (17), and journals that are not OA (28). The most common study designs were retrospective cohort studies and case series (seven each). The level of evidence was broadly distributed between Levels I, III, and IV (seven each). The averages for the Likert scales for medical accuracy and completeness were 4.4/6 and 1.92/3, respectively. <b>Conclusions:</b> Investigation into ChatGPT's response quality and use of peer-reviewed sources when prompted with archetypal pre-TKA and pre-THA questions found ChatGPT to provide mostly reliable responses based on fellowship-trained orthopedic surgeon review of 4.4/6 for accuracy and 1.92/3 for completeness despite a 64.22% rate of citing inaccurate references. This study suggests that until ChatGPT is proven to be a reliable source of valid information and references, patients must exercise extreme caution in directing their pre-TKA and THA questions to this medium.</p>","PeriodicalId":7358,"journal":{"name":"Advances in Orthopedics","volume":"2025 ","pages":"5534704"},"PeriodicalIF":1.6000,"publicationDate":"2025-01-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11729512/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Orthopedics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1155/aort/5534704","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Advances in artificial intelligence (AI), machine learning, and publicly accessible language model tools such as ChatGPT-3.5 continue to shape the landscape of modern medicine and patient education. ChatGPT's open access (OA), instant, human-sounding interface capable of carrying discussion on myriad topics makes it a potentially useful resource for patients seeking medical advice. As it pertains to orthopedic surgery, ChatGPT may become a source to answer common preoperative questions regarding total knee arthroplasty (TKA) and total hip arthroplasty (THA). Since ChatGPT can utilize the peer-reviewed literature to source its responses, this study seeks to characterize the validity of its responses to common TKA and THA questions and characterize the peer-reviewed literature that it uses to formulate its responses. Methods: Preoperative TKA and THA questions were formulated by fellowship-trained adult reconstruction surgeons based on common questions posed by patients in the clinical setting. Questions were inputted into ChatGPT with the initial request of using solely the peer-reviewed literature to generate its responses. The validity of each response was rated on a Likert scale by the fellowship-trained surgeons, and the sources utilized were characterized in terms of accuracy of comparison to existing publications, publication date, study design, level of evidence, journal of publication, journal impact factor based on the clarivate analytics factor tool, journal OA status, and whether the journal is based in the United States. Results: A total of 109 sources were cited by ChatGPT in its answers to 17 questions regarding TKA procedures and 16 THA procedures. Thirty-nine sources (36%) were deemed accurate or able to be directly traced to an existing publication. Of these, seven (18%) were identified as duplicates, yielding a total of 32 unique sources that were identified as accurate and further characterized. The most common characteristics of these sources included dates of publication between 2011 and 2015 (10), publication in The Journal of Bone and Joint Surgery (13), journal impact factors between 5.1 and 10.0 (17), internationally based journals (17), and journals that are not OA (28). The most common study designs were retrospective cohort studies and case series (seven each). The level of evidence was broadly distributed between Levels I, III, and IV (seven each). The averages for the Likert scales for medical accuracy and completeness were 4.4/6 and 1.92/3, respectively. Conclusions: Investigation into ChatGPT's response quality and use of peer-reviewed sources when prompted with archetypal pre-TKA and pre-THA questions found ChatGPT to provide mostly reliable responses based on fellowship-trained orthopedic surgeon review of 4.4/6 for accuracy and 1.92/3 for completeness despite a 64.22% rate of citing inaccurate references. This study suggests that until ChatGPT is proven to be a reliable source of valid information and references, patients must exercise extreme caution in directing their pre-TKA and THA questions to this medium.
背景:人工智能(AI)、机器学习和可公开访问的语言模型工具(如ChatGPT-3.5)的进步继续塑造现代医学和患者教育的格局。ChatGPT的开放访问(OA)、即时、人性化的界面能够就无数主题进行讨论,这使其成为寻求医疗建议的患者的潜在有用资源。由于它与骨科手术有关,ChatGPT可能成为解答全膝关节置换术(TKA)和全髋关节置换术(THA)术前常见问题的来源。由于ChatGPT可以利用同行评议的文献来获取其回答,因此本研究试图表征其对常见TKA和THA问题的回答的有效性,并表征其用于制定其回答的同行评议文献。方法:术前TKA和THA的问题是由研究员培训的成人重建外科医生根据患者在临床环境中提出的常见问题制定的。问题被输入到ChatGPT中,最初的要求是仅使用同行评审的文献来生成答案。每个回答的有效性由接受过奖学金培训的外科医生用李克特量表进行评分,并根据与现有出版物比较的准确性、出版日期、研究设计、证据水平、出版期刊、基于clarivate分析因子工具的期刊影响因子、期刊OA状态以及该期刊是否在美国进行特征描述。结果:ChatGPT在回答TKA程序的17个问题和THA程序的16个问题时共引用了109个来源。39个来源(36%)被认为是准确的或能够直接追溯到现有出版物。其中,7个(18%)被鉴定为重复,总共产生32个被鉴定为准确并进一步表征的独特来源。这些来源最常见的特征包括发表日期在2011年至2015年之间(10),发表于The Journal of Bone and Joint Surgery(13),期刊影响因子在5.1至10.0之间(17),国际期刊(17)和非OA期刊(28)。最常见的研究设计是回顾性队列研究和病例系列研究(各7例)。证据水平大致分布在I级、III级和IV级之间(各7个)。Likert量表的医疗准确性和完整性的平均值分别为4.4/6和1.92/3。结论:对ChatGPT的回答质量和使用同行评议的资料进行的调查发现,尽管引用不准确参考文献的比例为64.22%,但ChatGPT提供的回答大部分是可靠的,其准确性为4.4/6,完整性为1.92/3。本研究提示,在ChatGPT被证明是有效信息和参考的可靠来源之前,患者在将tka前和THA问题导向该媒介时必须非常谨慎。
期刊介绍:
Advances in Orthopedics is a peer-reviewed, Open Access journal that provides a forum for orthopaedics working on improving the quality of orthopedic health care. The journal publishes original research articles, review articles, and clinical studies related to arthroplasty, hand surgery, limb reconstruction, pediatric orthopaedics, sports medicine, trauma, spinal deformities, and orthopaedic oncology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


