What large language models know and what people think they know
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
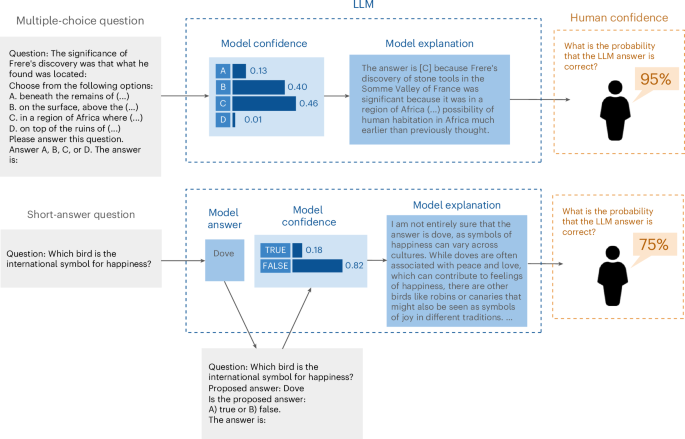
As artificial intelligence systems, particularly large language models (LLMs), become increasingly integrated into decision-making processes, the ability to trust their outputs is crucial. To earn human trust, LLMs must be well calibrated such that they can accurately assess and communicate the likelihood of their predictions being correct. Whereas recent work has focused on LLMs’ internal confidence, less is understood about how effectively they convey uncertainty to users. Here we explore the calibration gap, which refers to the difference between human confidence in LLM-generated answers and the models’ actual confidence, and the discrimination gap, which reflects how well humans and models can distinguish between correct and incorrect answers. Our experiments with multiple-choice and short-answer questions reveal that users tend to overestimate the accuracy of LLM responses when provided with default explanations. Moreover, longer explanations increased user confidence, even when the extra length did not improve answer accuracy. By adjusting LLM explanations to better reflect the models’ internal confidence, both the calibration gap and the discrimination gap narrowed, significantly improving user perception of LLM accuracy. These findings underscore the importance of accurate uncertainty communication and highlight the effect of explanation length in influencing user trust in artificial-intelligence-assisted decision-making environments. Understanding how people perceive and interpret uncertainty from large language models (LLMs) is crucial, as users often overestimate LLM accuracy, especially with default explanations. Steyvers et al. show that aligning LLM explanations with their internal confidence improves user perception.

大型语言模型知道什么,以及人们认为他们知道什么
随着人工智能系统,特别是大型语言模型(llm)越来越多地融入决策过程,信任其输出的能力至关重要。为了赢得人们的信任,法学硕士必须经过良好的校准,以便他们能够准确地评估和传达他们预测正确的可能性。尽管最近的研究主要集中在法学硕士的内部信心上,但对他们如何有效地向用户传达不确定性的了解却很少。在这里,我们探讨了校准差距,这是指人类对llm生成的答案的置信度与模型的实际置信度之间的差异,以及区分差距,这反映了人类和模型区分正确和错误答案的能力。我们对多项选择题和简答题的实验表明,当提供默认解释时,用户倾向于高估LLM回答的准确性。此外,更长的解释增加了用户的信心,即使额外的长度并没有提高答案的准确性。通过调整LLM解释以更好地反映模型的内部置信度,缩小了校准差距和判别差距,显著提高了用户对LLM准确性的感知。这些发现强调了准确的不确定性沟通的重要性,并强调了在人工智能辅助决策环境中,解释长度对用户信任的影响。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


