{"title":"Causal Discovery with Generalized Linear Models through Peeling Algorithms.","authors":"Minjie Wang, Xiaotong Shen, Wei Pan","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>This article presents a novel method for causal discovery with generalized structural equation models suited for analyzing diverse types of outcomes, including discrete, continuous, and mixed data. Causal discovery often faces challenges due to unmeasured confounders that hinder the identification of causal relationships. The proposed approach addresses this issue by developing two peeling algorithms (bottom-up and top-down) to ascertain causal relationships and valid instruments. This approach first reconstructs a super-graph to represent ancestral relationships between variables, using a peeling algorithm based on nodewise GLM regressions that exploit relationships between primary and instrumental variables. Then, it estimates parent-child effects from the ancestral relationships using another peeling algorithm while deconfounding a child's model with information borrowed from its parents' models. The article offers a theoretical analysis of the proposed approach, establishing conditions for model identifiability and providing statistical guarantees for accurately discovering parent-child relationships via the peeling algorithms. Furthermore, the article presents numerical experiments showcasing the effectiveness of our approach in comparison to state-of-the-art structure learning methods without confounders. Lastly, it demonstrates an application to Alzheimer's disease (AD), highlighting the method's utility in constructing gene-to-gene and gene-to-disease regulatory networks involving Single Nucleotide Polymorphisms (SNPs) for healthy and AD subjects.</p>","PeriodicalId":50161,"journal":{"name":"Journal of Machine Learning Research","volume":"25 ","pages":""},"PeriodicalIF":5.2000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11699566/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Machine Learning Research","FirstCategoryId":"94","ListUrlMain":"","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
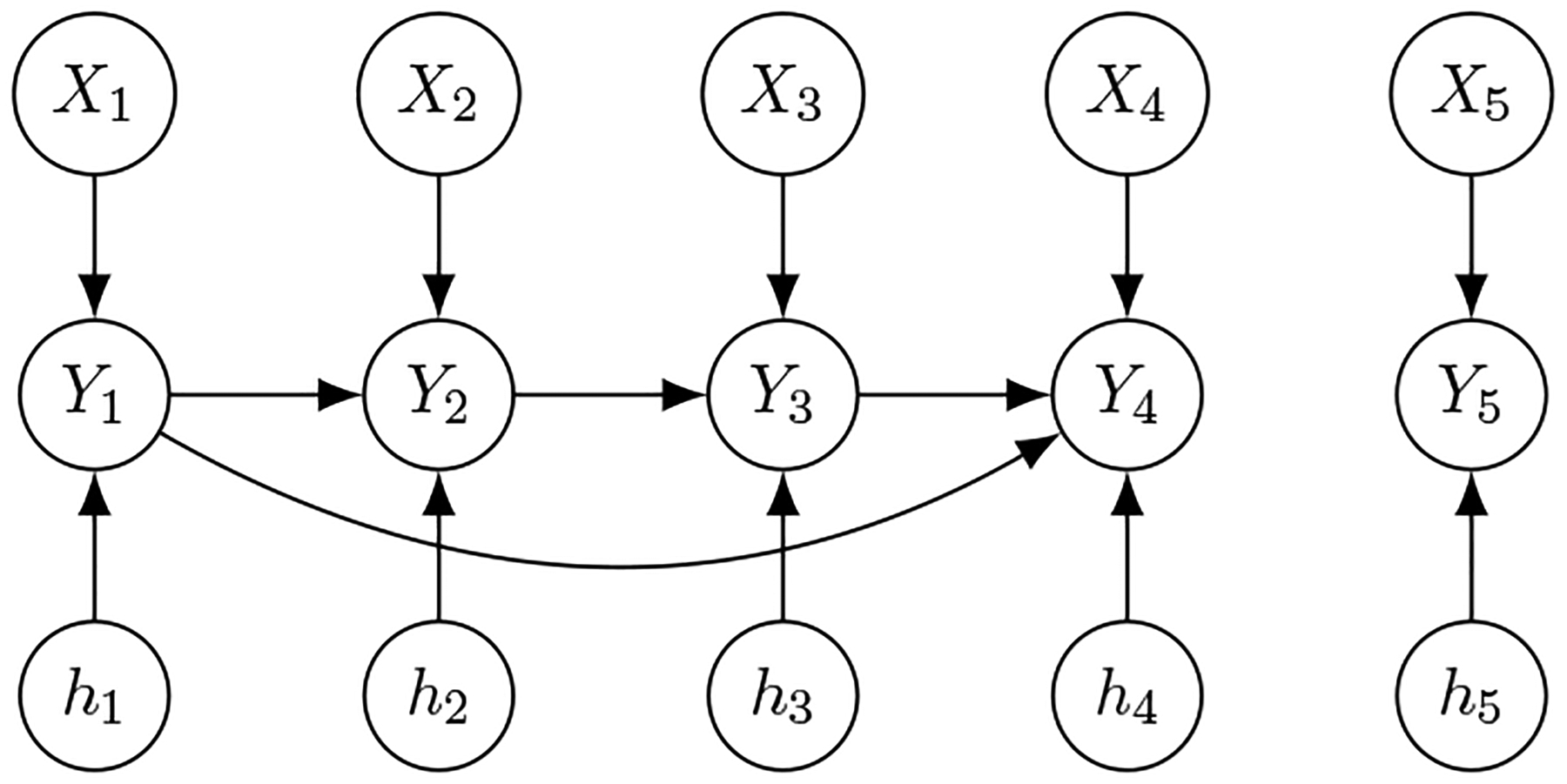
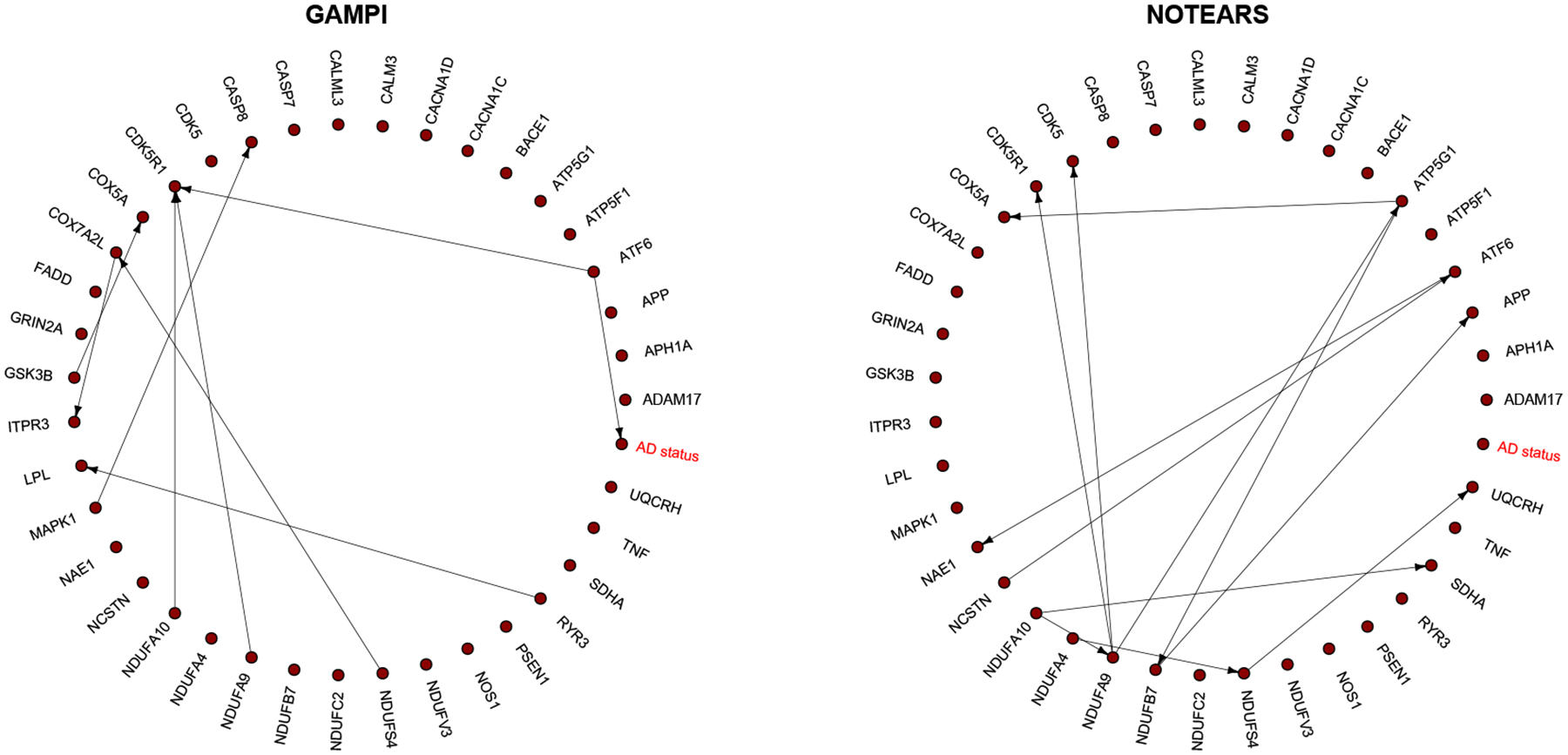
This article presents a novel method for causal discovery with generalized structural equation models suited for analyzing diverse types of outcomes, including discrete, continuous, and mixed data. Causal discovery often faces challenges due to unmeasured confounders that hinder the identification of causal relationships. The proposed approach addresses this issue by developing two peeling algorithms (bottom-up and top-down) to ascertain causal relationships and valid instruments. This approach first reconstructs a super-graph to represent ancestral relationships between variables, using a peeling algorithm based on nodewise GLM regressions that exploit relationships between primary and instrumental variables. Then, it estimates parent-child effects from the ancestral relationships using another peeling algorithm while deconfounding a child's model with information borrowed from its parents' models. The article offers a theoretical analysis of the proposed approach, establishing conditions for model identifiability and providing statistical guarantees for accurately discovering parent-child relationships via the peeling algorithms. Furthermore, the article presents numerical experiments showcasing the effectiveness of our approach in comparison to state-of-the-art structure learning methods without confounders. Lastly, it demonstrates an application to Alzheimer's disease (AD), highlighting the method's utility in constructing gene-to-gene and gene-to-disease regulatory networks involving Single Nucleotide Polymorphisms (SNPs) for healthy and AD subjects.
期刊介绍:
The Journal of Machine Learning Research (JMLR) provides an international forum for the electronic and paper publication of high-quality scholarly articles in all areas of machine learning. All published papers are freely available online.
JMLR has a commitment to rigorous yet rapid reviewing.
JMLR seeks previously unpublished papers on machine learning that contain:
new principled algorithms with sound empirical validation, and with justification of theoretical, psychological, or biological nature;
experimental and/or theoretical studies yielding new insight into the design and behavior of learning in intelligent systems;
accounts of applications of existing techniques that shed light on the strengths and weaknesses of the methods;
formalization of new learning tasks (e.g., in the context of new applications) and of methods for assessing performance on those tasks;
development of new analytical frameworks that advance theoretical studies of practical learning methods;
computational models of data from natural learning systems at the behavioral or neural level; or extremely well-written surveys of existing work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


