Fahri Onur Aydın, Burakhan Kürşat Aksoy, Ali Ceylan, Yusuf Berk Akbaş, Serhat Ermiş, Burçin Kepez Yıldız, Yusuf Yıldırım
{"title":"Readability and Appropriateness of Responses Generated by ChatGPT 3.5, ChatGPT 4.0, Gemini, and Microsoft Copilot for FAQs in Refractive Surgery.","authors":"Fahri Onur Aydın, Burakhan Kürşat Aksoy, Ali Ceylan, Yusuf Berk Akbaş, Serhat Ermiş, Burçin Kepez Yıldız, Yusuf Yıldırım","doi":"10.4274/tjo.galenos.2024.28234","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To assess the appropriateness and readability of large language model (LLM) chatbots' answers to frequently asked questions about refractive surgery.</p><p><strong>Materials and methods: </strong>Four commonly used LLM chatbots were asked 40 questions frequently asked by patients about refractive surgery. The appropriateness of the answers was evaluated by 2 experienced refractive surgeons. Readability was evaluated with 5 different indexes.</p><p><strong>Results: </strong>Based on the responses generated by the LLM chatbots, 45% (n=18) of the answers given by ChatGPT 3.5 were correct, while this rate was 52.5% (n=21) for ChatGPT 4.0, 87.5% (n=35) for Gemini, and 60% (n=24) for Copilot. In terms of readability, it was observed that all LLM chatbots were very difficult to read and required a university degree.</p><p><strong>Conclusion: </strong>These LLM chatbots, which are finding a place in our daily lives, can occasionally provide inappropriate answers. Although all were difficult to read, Gemini was the most successful LLM chatbot in terms of generating appropriate answers and was relatively better in terms of readability.</p>","PeriodicalId":23373,"journal":{"name":"Turkish Journal of Ophthalmology","volume":"54 6","pages":"313-317"},"PeriodicalIF":0.0000,"publicationDate":"2024-12-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11707452/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Turkish Journal of Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4274/tjo.galenos.2024.28234","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: To assess the appropriateness and readability of large language model (LLM) chatbots' answers to frequently asked questions about refractive surgery.
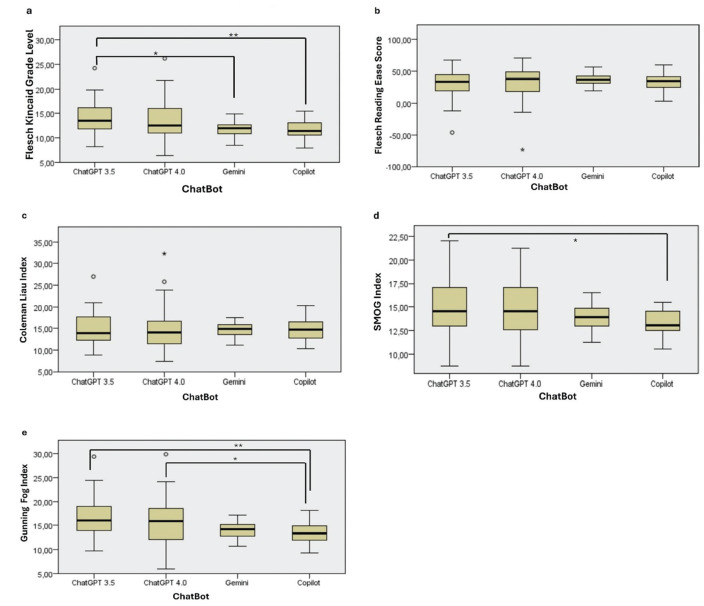
Materials and methods: Four commonly used LLM chatbots were asked 40 questions frequently asked by patients about refractive surgery. The appropriateness of the answers was evaluated by 2 experienced refractive surgeons. Readability was evaluated with 5 different indexes.
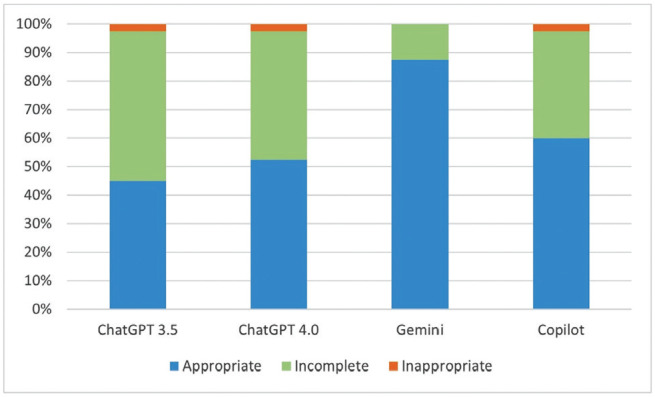
Results: Based on the responses generated by the LLM chatbots, 45% (n=18) of the answers given by ChatGPT 3.5 were correct, while this rate was 52.5% (n=21) for ChatGPT 4.0, 87.5% (n=35) for Gemini, and 60% (n=24) for Copilot. In terms of readability, it was observed that all LLM chatbots were very difficult to read and required a university degree.
Conclusion: These LLM chatbots, which are finding a place in our daily lives, can occasionally provide inappropriate answers. Although all were difficult to read, Gemini was the most successful LLM chatbot in terms of generating appropriate answers and was relatively better in terms of readability.
期刊介绍:
The Turkish Journal of Ophthalmology (TJO) is the only scientific periodical publication of the Turkish Ophthalmological Association and has been published since January 1929. In its early years, the journal was published in Turkish and French. Although there were temporary interruptions in the publication of the journal due to various challenges, the Turkish Journal of Ophthalmology has been published continually from 1971 to the present. The target audience includes specialists and physicians in training in ophthalmology in all relevant disciplines.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


