Samantha Eve Smith, Scott McColgan-Smith, Fiona Stewart, Julie Mardon, Victoria Ruth Tallentire
{"title":"Beyond reliability: assessing rater competence when using a behavioural marker system.","authors":"Samantha Eve Smith, Scott McColgan-Smith, Fiona Stewart, Julie Mardon, Victoria Ruth Tallentire","doi":"10.1186/s41077-024-00329-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Behavioural marker systems are used across several healthcare disciplines to assess behavioural (non-technical) skills, but rater training is variable, and inter-rater reliability is generally poor. Inter-rater reliability provides data about the tool, but not the competence of individual raters. This study aimed to test the inter-rater reliability of a new behavioural marker system (PhaBS - pharmacists' behavioural skills) with clinically experienced faculty raters and near-peer raters. It also aimed to assess rater competence when using PhaBS after brief familiarisation, by assessing completeness, agreement with an expert rater, ability to rank performance, stringency or leniency, and avoidance of the halo effect.</p><p><strong>Methods: </strong>Clinically experienced faculty raters and near-peer raters attended a 30-min PhaBS familiarisation session. This was immediately followed by a marking session in which they rated a trainee pharmacist's behavioural skills in three scripted immersive acute care simulated scenarios, demonstrating good, mediocre, and poor performances respectively. Inter-rater reliability in each group was calculated using the two-way random, absolute agreement single-measures intra-class correlation co-efficient (ICC). Differences in individual rater competence in each domain were compared using Pearson's chi-squared test.</p><p><strong>Results: </strong>The ICC for experienced faculty raters was good at 0.60 (0.48-0.72) and for near-peer raters was poor at 0.38 (0.27-0.54). Of experienced faculty raters, 5/9 were competent in all domains versus 2/13 near-peer raters (difference not statistically significant). There was no statistically significant difference between the abilities of clinically experienced versus near-peer raters in agreement with an expert rater, ability to rank performance, stringency or leniency, or avoidance of the halo effect. The only statistically significant difference between groups was ability to compete the assessment (9/9 experienced faculty raters versus 6/13 near-peer raters, p = 0.0077).</p><p><strong>Conclusions: </strong>Experienced faculty have acceptable inter-rater reliability when using PhaBS, consistent with other behaviour marker systems; however, not all raters are competent. Competence measures for other assessments can be helpfully applied to behavioural marker systems. When using behavioural marker systems for assessment, educators must start using such rater competence frameworks. This is important to ensure fair and accurate assessments for learners, to provide educators with information about rater training programmes, and to provide individual raters with meaningful feedback.</p>","PeriodicalId":72108,"journal":{"name":"Advances in simulation (London, England)","volume":"9 1","pages":"55"},"PeriodicalIF":4.7000,"publicationDate":"2024-12-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11687013/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in simulation (London, England)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41077-024-00329-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Behavioural marker systems are used across several healthcare disciplines to assess behavioural (non-technical) skills, but rater training is variable, and inter-rater reliability is generally poor. Inter-rater reliability provides data about the tool, but not the competence of individual raters. This study aimed to test the inter-rater reliability of a new behavioural marker system (PhaBS - pharmacists' behavioural skills) with clinically experienced faculty raters and near-peer raters. It also aimed to assess rater competence when using PhaBS after brief familiarisation, by assessing completeness, agreement with an expert rater, ability to rank performance, stringency or leniency, and avoidance of the halo effect.
Methods: Clinically experienced faculty raters and near-peer raters attended a 30-min PhaBS familiarisation session. This was immediately followed by a marking session in which they rated a trainee pharmacist's behavioural skills in three scripted immersive acute care simulated scenarios, demonstrating good, mediocre, and poor performances respectively. Inter-rater reliability in each group was calculated using the two-way random, absolute agreement single-measures intra-class correlation co-efficient (ICC). Differences in individual rater competence in each domain were compared using Pearson's chi-squared test.
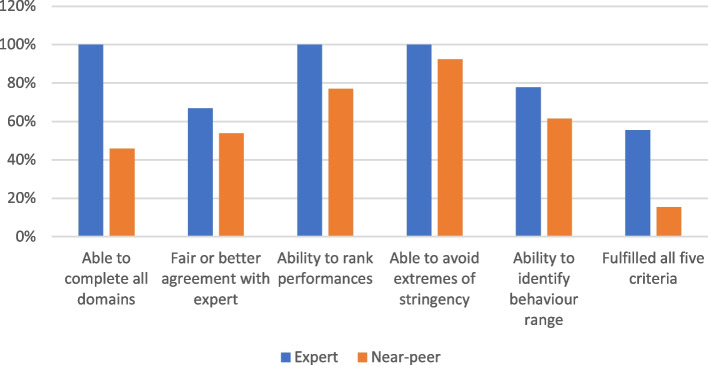
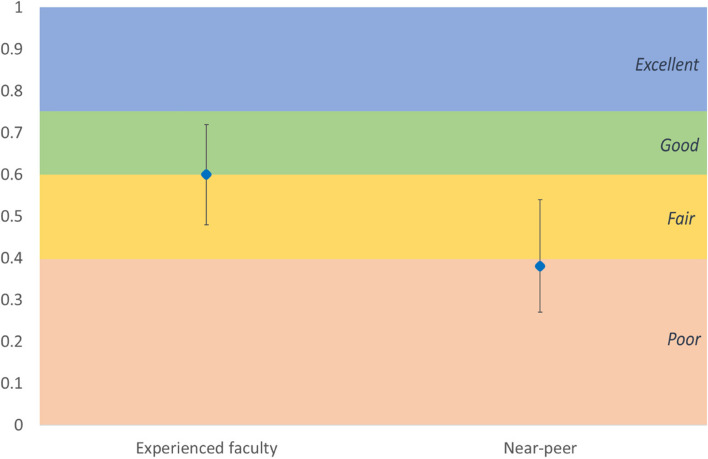
Results: The ICC for experienced faculty raters was good at 0.60 (0.48-0.72) and for near-peer raters was poor at 0.38 (0.27-0.54). Of experienced faculty raters, 5/9 were competent in all domains versus 2/13 near-peer raters (difference not statistically significant). There was no statistically significant difference between the abilities of clinically experienced versus near-peer raters in agreement with an expert rater, ability to rank performance, stringency or leniency, or avoidance of the halo effect. The only statistically significant difference between groups was ability to compete the assessment (9/9 experienced faculty raters versus 6/13 near-peer raters, p = 0.0077).
Conclusions: Experienced faculty have acceptable inter-rater reliability when using PhaBS, consistent with other behaviour marker systems; however, not all raters are competent. Competence measures for other assessments can be helpfully applied to behavioural marker systems. When using behavioural marker systems for assessment, educators must start using such rater competence frameworks. This is important to ensure fair and accurate assessments for learners, to provide educators with information about rater training programmes, and to provide individual raters with meaningful feedback.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


