Enhancing human phenotype ontology term extraction through synthetic case reports and embedding-based retrieval: A novel approach for improved biomedical data annotation
Q2 Medicine
引用次数: 0
Abstract
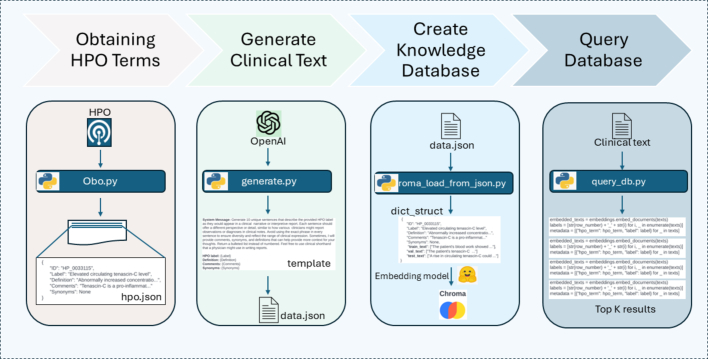
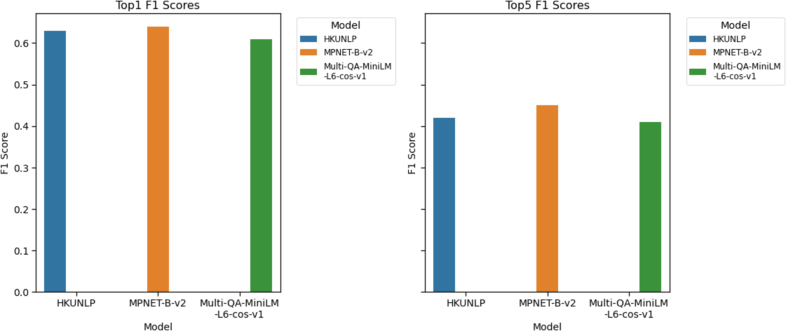
With the increasing utilization of exome and genome sequencing in clinical and research genetics, accurate and automated extraction of human phenotype ontology (HPO) terms from clinical texts has become imperative. Traditional methods for HPO term extraction, such as PhenoTagger, often face limitations in coverage and precision. In this study, we propose a novel approach that leverages large language models (LLMs) to generate synthetic sentences with clinical context, which were semantically encoded into vector embeddings. These embeddings are linked to HPO terms, creating a robust knowledgebase that facilitates precise information retrieval. Our method circumvents the known issue of LLM hallucinations by storing and querying these embeddings within a true database, ensuring accurate context matching without the need for a predictive model. We evaluated the performance of three different embedding models, all of which demonstrated substantial improvements over PhenoTagger. Top recall (sensitivity), precision (positive-predictive value, PPV), and F1 are 0.64, 0.64, and 0.64, respectively, which were 31%, 10%, and 21% better than PhenoTagger. Furthermore, optimal performance was achieved when we combined the best performing embedding model with PhenoTagger (a.k.a. Fused model), resulting in recall (sensitivity), precision (PPV), and F1 values of 0.7, 0.7, and 0.7, respectively, which are 10%, 10%, and 10% better than the best embedding models. Our findings underscore the potential of this integrated approach to enhance the precision and reliability of HPO term extraction, offering a scalable and effective solution for biomedical data annotation.
通过综合病例报告和基于嵌入的检索增强人类表型本体术语提取:一种改进生物医学数据注释的新方法。
随着外显子组和基因组测序在临床和研究遗传学中的应用越来越多,从临床文本中准确、自动地提取人类表型本体论(HPO)术语已经变得势在必行。传统的HPO术语提取方法,如PhenoTagger,往往面临覆盖范围和精度的限制。在本研究中,我们提出了一种利用大型语言模型(llm)生成具有临床上下文的合成句子的新方法,这些句子在语义上被编码为向量嵌入。这些嵌入与HPO术语相关联,创建了一个健壮的知识库,方便了精确的信息检索。我们的方法通过在真实的数据库中存储和查询这些嵌入,避免了已知的LLM幻觉问题,确保了准确的上下文匹配,而不需要预测模型。我们评估了三种不同嵌入模型的性能,它们都比PhenoTagger有了实质性的改进。toprecall (sensitivity)、precision (positive-predictive value, PPV)和F1分别为0.64、0.64和0.64,分别比PhenoTagger高31%、10%和21%。此外,当我们将表现最好的嵌入模型与PhenoTagger(又称融合模型)结合时,获得了最优的性能,召回率(灵敏度),精度(PPV)和F1值分别为0.7,0.7和0.7,分别比最佳嵌入模型高10%,10%和10%。我们的研究结果强调了这种集成方法在提高HPO术语提取的精度和可靠性方面的潜力,为生物医学数据标注提供了一种可扩展和有效的解决方案。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Pathology Informatics
Medicine-Pathology and Forensic Medicine
CiteScore
3.70
自引率
0.00%
发文量
2
审稿时长
18 weeks
期刊介绍:
The Journal of Pathology Informatics (JPI) is an open access peer-reviewed journal dedicated to the advancement of pathology informatics. This is the official journal of the Association for Pathology Informatics (API). The journal aims to publish broadly about pathology informatics and freely disseminate all articles worldwide. This journal is of interest to pathologists, informaticians, academics, researchers, health IT specialists, information officers, IT staff, vendors, and anyone with an interest in informatics. We encourage submissions from anyone with an interest in the field of pathology informatics. We publish all types of papers related to pathology informatics including original research articles, technical notes, reviews, viewpoints, commentaries, editorials, symposia, meeting abstracts, book reviews, and correspondence to the editors. All submissions are subject to rigorous peer review by the well-regarded editorial board and by expert referees in appropriate specialties.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


