Meysam Alizadeh, Maël Kubli, Zeynab Samei, Shirin Dehghani, Mohammadmasiha Zahedivafa, Juan D Bermeo, Maria Korobeynikova, Fabrizio Gilardi
{"title":"Open-source LLMs for text annotation: a practical guide for model setting and fine-tuning.","authors":"Meysam Alizadeh, Maël Kubli, Zeynab Samei, Shirin Dehghani, Mohammadmasiha Zahedivafa, Juan D Bermeo, Maria Korobeynikova, Fabrizio Gilardi","doi":"10.1007/s42001-024-00345-9","DOIUrl":null,"url":null,"abstract":"<p><p>This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis and to establish a baseline performance benchmark that demonstrates the models' effectiveness. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT <math><mo>-</mo></math> 3.5 and GPT-4, though still lagging behind fine-tuned GPT <math><mo>-</mo></math> 3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s42001-024-00345-9.</p>","PeriodicalId":29946,"journal":{"name":"Journal of Computational Social Science","volume":"8 1","pages":"17"},"PeriodicalIF":2.3000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11655591/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Computational Social Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s42001-024-00345-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/18 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"SOCIAL SCIENCES, MATHEMATICAL METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
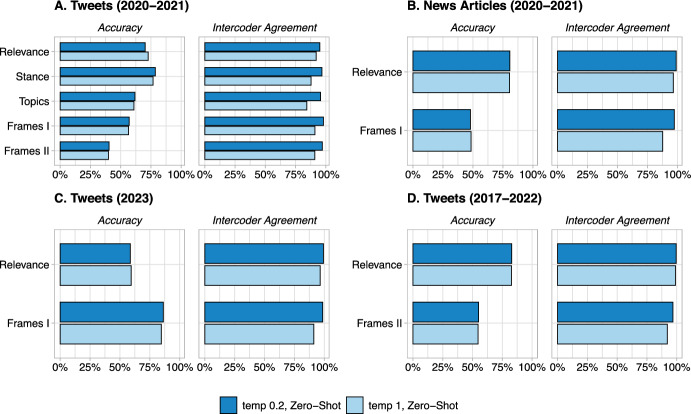
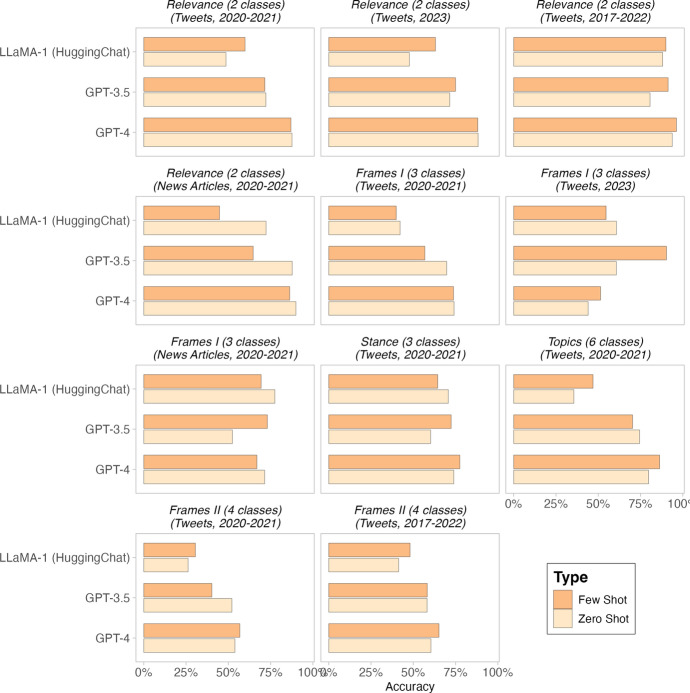
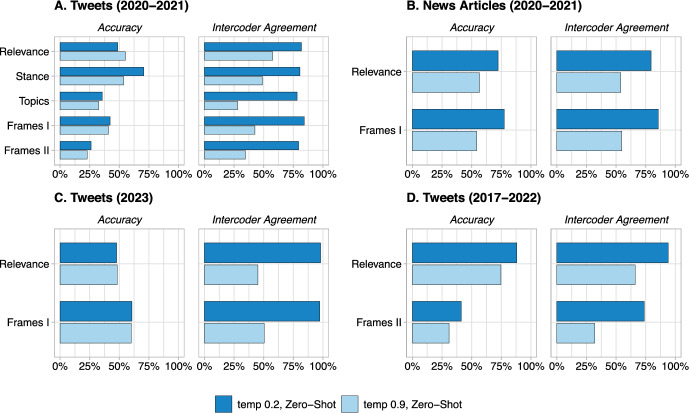
This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis and to establish a baseline performance benchmark that demonstrates the models' effectiveness. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT 3.5 and GPT-4, though still lagging behind fine-tuned GPT 3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.
Supplementary information: The online version contains supplementary material available at 10.1007/s42001-024-00345-9.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


