{"title":"Enhancing pharmacogenomic data accessibility and drug safety with large language models: a case study with Llama3.1.","authors":"Dan Li, Leihong Wu, Ying-Chi Lin, Ho-Yin Huang, Ebony Cotton, Qi Liu, Ru Chen, Ruihao Huang, Yifan Zhang, Joshua Xu","doi":"10.3389/ebm.2024.10393","DOIUrl":null,"url":null,"abstract":"<p><p>Pharmacogenomics (PGx) holds the promise of personalizing medical treatments based on individual genetic profiles, thereby enhancing drug efficacy and safety. However, the current landscape of PGx research is hindered by fragmented data sources, time-consuming manual data extraction processes, and the need for comprehensive and up-to-date information. This study aims to address these challenges by evaluating the ability of Large Language Models (LLMs), specifically Llama3.1-70B, to automate and improve the accuracy of PGx information extraction from the FDA Table of Pharmacogenomic Biomarkers in Drug Labeling (FDA PGx Biomarker table), which is well-structured with drug names, biomarkers, therapeutic area, and related labeling texts. Our primary goal was to test the feasibility of LLMs in streamlining PGx data extraction, as an alternative to traditional, labor-intensive approaches. Llama3.1-70B achieved 91.4% accuracy in identifying drug-biomarker pairs from single labeling texts and 82% from mixed texts, with over 85% consistency in aligning extracted PGx categories from FDA PGx Biomarker table and relevant scientific abstracts, demonstrating its effectiveness for PGx data extraction. By integrating data from diverse sources, including scientific abstracts, this approach can support pharmacologists, regulatory bodies, and healthcare researchers in updating PGx resources more efficiently, making critical information more accessible for applications in personalized medicine. In addition, this approach shows potential of discovering novel PGx information, particularly of underrepresented minority ethnic groups. This study highlights the ability of LLMs to enhance the efficiency and completeness of PGx research, thus laying a foundation for advancements in personalized medicine by ensuring that drug therapies are tailored to the genetic profiles of diverse populations.</p>","PeriodicalId":12163,"journal":{"name":"Experimental Biology and Medicine","volume":"249 ","pages":"10393"},"PeriodicalIF":2.7000,"publicationDate":"2024-12-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11650518/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Experimental Biology and Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3389/ebm.2024.10393","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
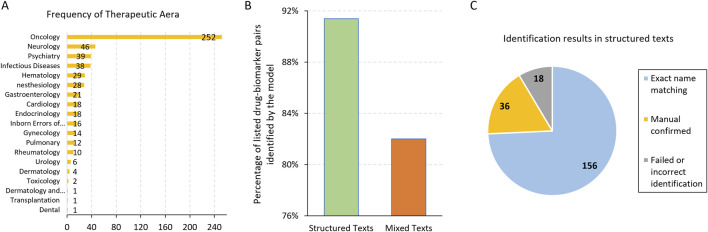
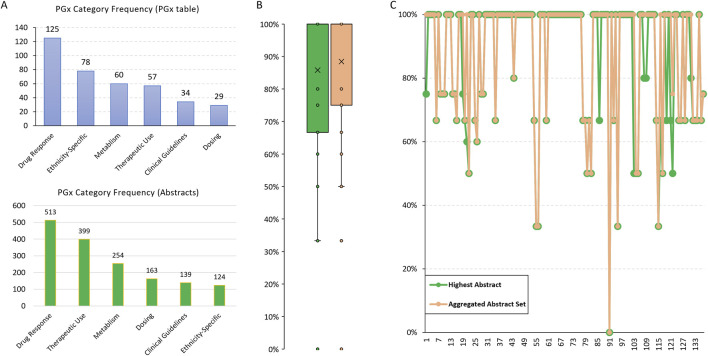
Pharmacogenomics (PGx) holds the promise of personalizing medical treatments based on individual genetic profiles, thereby enhancing drug efficacy and safety. However, the current landscape of PGx research is hindered by fragmented data sources, time-consuming manual data extraction processes, and the need for comprehensive and up-to-date information. This study aims to address these challenges by evaluating the ability of Large Language Models (LLMs), specifically Llama3.1-70B, to automate and improve the accuracy of PGx information extraction from the FDA Table of Pharmacogenomic Biomarkers in Drug Labeling (FDA PGx Biomarker table), which is well-structured with drug names, biomarkers, therapeutic area, and related labeling texts. Our primary goal was to test the feasibility of LLMs in streamlining PGx data extraction, as an alternative to traditional, labor-intensive approaches. Llama3.1-70B achieved 91.4% accuracy in identifying drug-biomarker pairs from single labeling texts and 82% from mixed texts, with over 85% consistency in aligning extracted PGx categories from FDA PGx Biomarker table and relevant scientific abstracts, demonstrating its effectiveness for PGx data extraction. By integrating data from diverse sources, including scientific abstracts, this approach can support pharmacologists, regulatory bodies, and healthcare researchers in updating PGx resources more efficiently, making critical information more accessible for applications in personalized medicine. In addition, this approach shows potential of discovering novel PGx information, particularly of underrepresented minority ethnic groups. This study highlights the ability of LLMs to enhance the efficiency and completeness of PGx research, thus laying a foundation for advancements in personalized medicine by ensuring that drug therapies are tailored to the genetic profiles of diverse populations.
期刊介绍:
Experimental Biology and Medicine (EBM) is a global, peer-reviewed journal dedicated to the publication of multidisciplinary and interdisciplinary research in the biomedical sciences. EBM provides both research and review articles as well as meeting symposia and brief communications. Articles in EBM represent cutting edge research at the overlapping junctions of the biological, physical and engineering sciences that impact upon the health and welfare of the world''s population.
Topics covered in EBM include: Anatomy/Pathology; Biochemistry and Molecular Biology; Bioimaging; Biomedical Engineering; Bionanoscience; Cell and Developmental Biology; Endocrinology and Nutrition; Environmental Health/Biomarkers/Precision Medicine; Genomics, Proteomics, and Bioinformatics; Immunology/Microbiology/Virology; Mechanisms of Aging; Neuroscience; Pharmacology and Toxicology; Physiology; Stem Cell Biology; Structural Biology; Systems Biology and Microphysiological Systems; and Translational Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


