Zhixue Zhao, James Thomas, Gregory Kell, Claire Stansfield, Mark Clowes, Sergio Graziosi, Jeff Brunton, Iain James Marshall, Mark Stevenson
{"title":"The FAIR database: facilitating access to public health research literature.","authors":"Zhixue Zhao, James Thomas, Gregory Kell, Claire Stansfield, Mark Clowes, Sergio Graziosi, Jeff Brunton, Iain James Marshall, Mark Stevenson","doi":"10.1093/jamiaopen/ooae139","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>In public health, access to research literature is critical to informing decision-making and to identify knowledge gaps. However, identifying relevant research is not a straightforward task since public health interventions are often complex, can have positive and negative impacts on health inequalities and are applied in diverse and rapidly evolving settings. We developed a \"living\" database of public health research literature to facilitate access to this information using Natural Language Processing tools.</p><p><strong>Materials and methods: </strong>Classifiers were identified to identify the study design (eg, cohort study or clinical trial) and relationship to factors that may be relevant to inequalities using the PROGRESS-Plus classification scheme. Training data were obtained from existing MEDLINE labels and from a set of systematic reviews in which studies were annotated with PROGRESS-Plus categories.</p><p><strong>Results: </strong>Evaluation of the classifiers showed that the study type classifier achieved average precision and recall of 0.803 and 0.930, respectively. The PROGRESS-Plus classification proved more challenging with average precision and recall of 0.608 and 0.534. The FAIR database uses information provided by these classifiers to facilitate access to inequality-related public health literature.</p><p><strong>Discussion: </strong>Previous work on automation of evidence synthesis has focused on clinical areas rather than public health, despite the need being arguably greater.</p><p><strong>Conclusion: </strong>The development of the FAIR database demonstrates that it is possible to create a publicly accessible and regularly updated database of public health research literature focused on inequalities. The database is freely available from https://eppi.ioe.ac.uk/eppi-vis/Fair.</p><p><strong>Netscc id number: </strong>NIHR133603.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"7 4","pages":"ooae139"},"PeriodicalIF":3.4000,"publicationDate":"2024-12-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11641844/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooae139","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: In public health, access to research literature is critical to informing decision-making and to identify knowledge gaps. However, identifying relevant research is not a straightforward task since public health interventions are often complex, can have positive and negative impacts on health inequalities and are applied in diverse and rapidly evolving settings. We developed a "living" database of public health research literature to facilitate access to this information using Natural Language Processing tools.
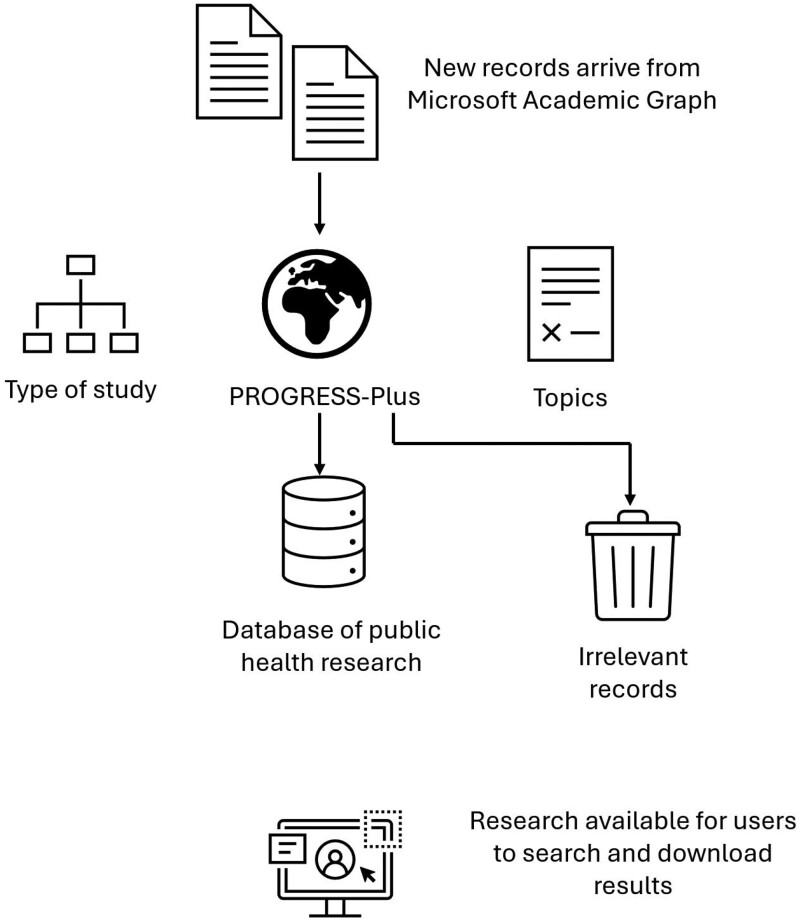
Materials and methods: Classifiers were identified to identify the study design (eg, cohort study or clinical trial) and relationship to factors that may be relevant to inequalities using the PROGRESS-Plus classification scheme. Training data were obtained from existing MEDLINE labels and from a set of systematic reviews in which studies were annotated with PROGRESS-Plus categories.
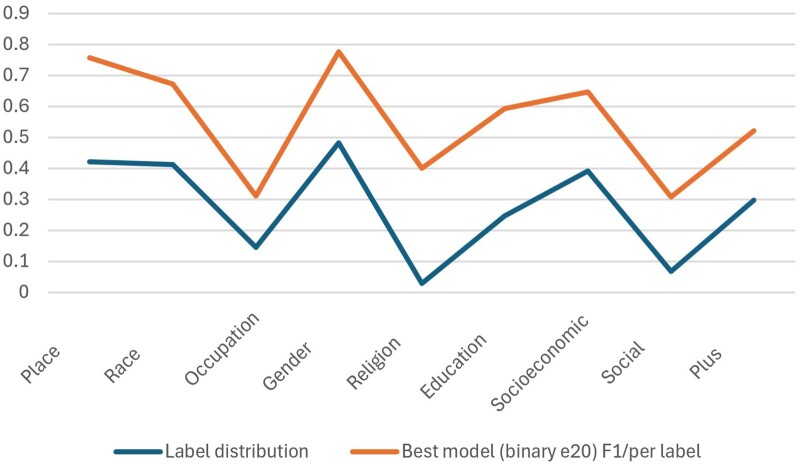
Results: Evaluation of the classifiers showed that the study type classifier achieved average precision and recall of 0.803 and 0.930, respectively. The PROGRESS-Plus classification proved more challenging with average precision and recall of 0.608 and 0.534. The FAIR database uses information provided by these classifiers to facilitate access to inequality-related public health literature.
Discussion: Previous work on automation of evidence synthesis has focused on clinical areas rather than public health, despite the need being arguably greater.
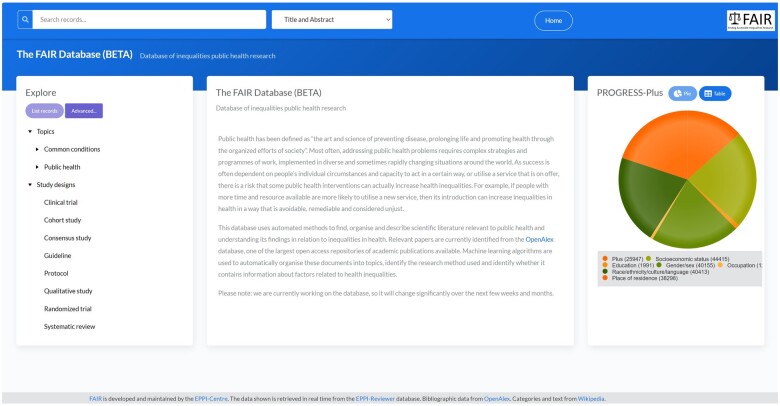
Conclusion: The development of the FAIR database demonstrates that it is possible to create a publicly accessible and regularly updated database of public health research literature focused on inequalities. The database is freely available from https://eppi.ioe.ac.uk/eppi-vis/Fair.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


