Sherif Elmitwalli, John Mehegan, Allen Gallagher, Raouf Alebshehy
{"title":"Enhancing sentiment and intent analysis in public health via fine-tuned Large Language Models on tobacco and e-cigarette-related tweets.","authors":"Sherif Elmitwalli, John Mehegan, Allen Gallagher, Raouf Alebshehy","doi":"10.3389/fdata.2024.1501154","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Accurate sentiment analysis and intent categorization of tobacco and e-cigarette-related social media content are critical for public health research, yet they necessitate specialized natural language processing approaches.</p><p><strong>Objective: </strong>To compare pre-trained and fine-tuned Flan-T5 models for intent classification and sentiment analysis of tobacco and e-cigarette tweets, demonstrating the effectiveness of pre-training a lightweight large language model for domain specific tasks.</p><p><strong>Methods: </strong>Three Flan-T5 classification models were developed: (1) tobacco intent, (2) e-cigarette intent, and (3) sentiment analysis. Domain-specific datasets with tobacco and e-cigarette tweets were created using GPT-4 and validated by tobacco control specialists using a rigorous evaluation process. A standardized rubric and consensus mechanism involving domain specialists ensured high-quality datasets. The Flan-T5 Large Language Models were fine-tuned using Low-Rank Adaptation and evaluated against pre-trained baselines on the datasets using accuracy performance metrics. To further assess model generalizability and robustness, the fine-tuned models were evaluated on real-world tweets collected around the COP9 event.</p><p><strong>Results: </strong>In every task, fine-tuned models performed much better than pre-trained models. Compared to the pre-trained model's accuracy of 0.33, the fine-tuned model achieved an overall accuracy of 0.91 for tobacco intent classification. The fine-tuned model achieved an accuracy of 0.93 for e-cigarette intent, which is higher than the accuracy of 0.36 for the pre-trained model. The fine-tuned model significantly outperformed the pre-trained model's accuracy of 0.65 in sentiment analysis, achieving an accuracy of 0.94 for sentiments.</p><p><strong>Conclusion: </strong>The effectiveness of lightweight Flan-T5 models in analyzing tweets associated with tobacco and e-cigarette is significantly improved by domain-specific fine-tuning, providing highly accurate instruments for tracking public conversation on tobacco and e-cigarette. The involvement of domain specialists in dataset validation ensured that the generated content accurately represented real-world discussions, thereby enhancing the quality and reliability of the results. Research on tobacco control and the formulation of public policy could be informed by these findings.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"7 ","pages":"1501154"},"PeriodicalIF":2.4000,"publicationDate":"2024-11-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11634848/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2024.1501154","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Accurate sentiment analysis and intent categorization of tobacco and e-cigarette-related social media content are critical for public health research, yet they necessitate specialized natural language processing approaches.
Objective: To compare pre-trained and fine-tuned Flan-T5 models for intent classification and sentiment analysis of tobacco and e-cigarette tweets, demonstrating the effectiveness of pre-training a lightweight large language model for domain specific tasks.
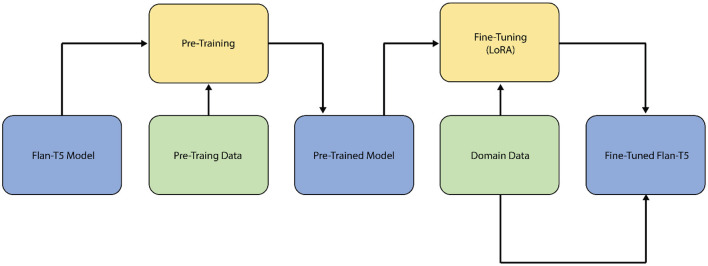
Methods: Three Flan-T5 classification models were developed: (1) tobacco intent, (2) e-cigarette intent, and (3) sentiment analysis. Domain-specific datasets with tobacco and e-cigarette tweets were created using GPT-4 and validated by tobacco control specialists using a rigorous evaluation process. A standardized rubric and consensus mechanism involving domain specialists ensured high-quality datasets. The Flan-T5 Large Language Models were fine-tuned using Low-Rank Adaptation and evaluated against pre-trained baselines on the datasets using accuracy performance metrics. To further assess model generalizability and robustness, the fine-tuned models were evaluated on real-world tweets collected around the COP9 event.
Results: In every task, fine-tuned models performed much better than pre-trained models. Compared to the pre-trained model's accuracy of 0.33, the fine-tuned model achieved an overall accuracy of 0.91 for tobacco intent classification. The fine-tuned model achieved an accuracy of 0.93 for e-cigarette intent, which is higher than the accuracy of 0.36 for the pre-trained model. The fine-tuned model significantly outperformed the pre-trained model's accuracy of 0.65 in sentiment analysis, achieving an accuracy of 0.94 for sentiments.
Conclusion: The effectiveness of lightweight Flan-T5 models in analyzing tweets associated with tobacco and e-cigarette is significantly improved by domain-specific fine-tuning, providing highly accurate instruments for tracking public conversation on tobacco and e-cigarette. The involvement of domain specialists in dataset validation ensured that the generated content accurately represented real-world discussions, thereby enhancing the quality and reliability of the results. Research on tobacco control and the formulation of public policy could be informed by these findings.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


