Kernel approximation using analogue in-memory computing
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Kernel functions are vital ingredients of several machine learning (ML) algorithms but often incur substantial memory and computational costs. We introduce an approach to kernel approximation in ML algorithms suitable for mixed-signal analogue in-memory computing (AIMC) architectures. Analogue in-memory kernel approximation addresses the performance bottlenecks of conventional kernel-based methods by executing most operations in approximate kernel methods directly in memory. The IBM HERMES project chip, a state-of-the-art phase-change memory-based AIMC chip, is utilized for the hardware demonstration of kernel approximation. Experimental results show that our method maintains high accuracy, with less than a 1% drop in kernel-based ridge classification benchmarks and within 1% accuracy on the long-range arena benchmark for kernelized attention in transformer neural networks. Compared to traditional digital accelerators, our approach is estimated to deliver superior energy efficiency and lower power consumption. These findings highlight the potential of heterogeneous AIMC architectures to enhance the efficiency and scalability of ML applications. A kernel approximation method that enables linear-complexity attention computation via analogue in-memory computing (AIMC) to deliver superior energy efficiency is demonstrated on a multicore AIMC chip.
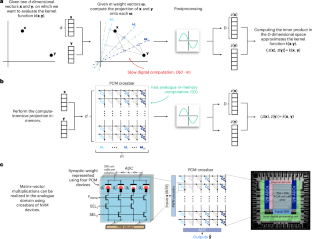

核近似使用模拟内存计算
核函数是几种机器学习(ML)算法的重要组成部分,但通常会产生大量的内存和计算成本。我们介绍了一种适用于混合信号模拟内存计算(AIMC)架构的机器学习算法中的核逼近方法。模拟内存核近似通过直接在内存中执行近似核方法中的大多数操作来解决传统基于核的方法的性能瓶颈。IBM HERMES项目芯片是一种最先进的基于相变存储器的AIMC芯片,用于内核逼近的硬件演示。实验结果表明,该方法保持了较高的准确率,在变压器神经网络中,基于核的脊分类基准的准确率下降不到1%,在核关注的远程竞技场基准的准确率在1%以内。与传统的数字加速器相比,我们的方法估计可以提供更高的能源效率和更低的功耗。这些发现突出了异构AIMC架构在提高机器学习应用程序的效率和可扩展性方面的潜力。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


