Rethinking residual connection in training large-scale spiking neural networks
IF 5.5
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
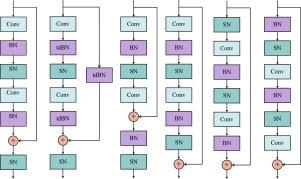
Spiking Neural Network (SNN) is known as the most famous brain-inspired model, but the non-differentiable spiking mechanism makes it hard to train large-scale SNNs. To facilitate the training of large-scale SNNs, many training methods are borrowed from Artificial Neural Networks (ANNs), among which deep residual learning is the most commonly used. But the unique features of SNNs make prior intuition built upon ANNs not available for SNNs. Although there are a few studies that have made some pioneer attempts on the topology of Spiking ResNet, the advantages of different connections remain unclear. To tackle this issue, we analyze the merits and limitations of various residual connections and empirically demonstrate our ideas with extensive experiments. Then, based on our observations, we abstract the best-performing connections into densely additive (DA) connection, extend such a concept to other topologies, and propose four architectures for training large-scale SNNs, termed DANet, which brings up to 13.24 accuracy gain on ImageNet. Besides, in order to present a detailed methodology for designing the topology of large-scale SNNs, we further conduct in-depth discussions on their applicable scenarios in terms of their performance on various scales of datasets and demonstrate their advantages over prior architectures. At a low training expense, our best-performing ResNet-50/101/152 obtain 73.71/76.13/77.22 top-1 accuracy on ImageNet with 4 time steps. We believe that this work shall give more insights for future works to design the topology of their networks and promote the development of large-scale SNNs. The code will be publicly available.
求助全文
约1分钟内获得全文
求助全文
来源期刊

Neurocomputing
工程技术-计算机:人工智能
CiteScore
13.10
自引率
10.00%
发文量
1382
审稿时长
70 days
期刊介绍:
Neurocomputing publishes articles describing recent fundamental contributions in the field of neurocomputing. Neurocomputing theory, practice and applications are the essential topics being covered.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


