Huaquan Su, Junwei Li, Li Guo, Wanshuo Wang, Yongjiao Yang, You Wen, Kai Li, Pingyan Mo
{"title":"Massive Data HBase Storage Method for Electronic Archive Management","authors":"Huaquan Su, Junwei Li, Li Guo, Wanshuo Wang, Yongjiao Yang, You Wen, Kai Li, Pingyan Mo","doi":"10.1002/nem.2308","DOIUrl":null,"url":null,"abstract":"<div>\n \n <p>The acceleration of the digitalization process in enterprise and university education management has generated a massive amount of electronic archive data. In order to improve the intelligence, storage quality, and efficiency of electronic records management and achieve efficient storage and fast retrieval of data storage models, this study proposes a massive data storage model based on HBase and its retrieval optimization scheme design. In addition, HDFS is introduced to construct a two-level storage structure and optimize values to improve the scalability and load balancing of HBase, and the retrieval efficiency of the HBase storage model is improved through SL-TCR and BF filters. The results indicated that HDFS could automatically recover data after node, network partition, and NameNode failures. The write time of HBase was 56 s, which was 132 and 246 s less than Cassandra and CockroachDB. The query latency was reduced by 23% and 32%, and the query time was reduced by 9988.51 ms, demonstrating high reliability and efficiency. The delay of BF-SL-TCL was 1379.28 s after 1000 searches, which was 224.78 and 212.74 s less than SL-TCL and Blockchain Retrieval Acceleration and reduced the delay under high search times. In summary, this storage model has obvious advantages in storing massive amounts of electronic archive data and has high security and retrieval efficiency, which provides important reference for the design of storage models for future electronic archive management. The storage model designed by the research institute has obvious advantages in storing massive electronic archive data, solving the problem of lack of scalability in electronic archive management when facing massive data, and has high security and retrieval efficiency. It has important reference for the design of storage models for future electronic archive management.</p>\n </div>","PeriodicalId":14154,"journal":{"name":"International Journal of Network Management","volume":"35 1","pages":""},"PeriodicalIF":2.6000,"publicationDate":"2024-10-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Network Management","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/nem.2308","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
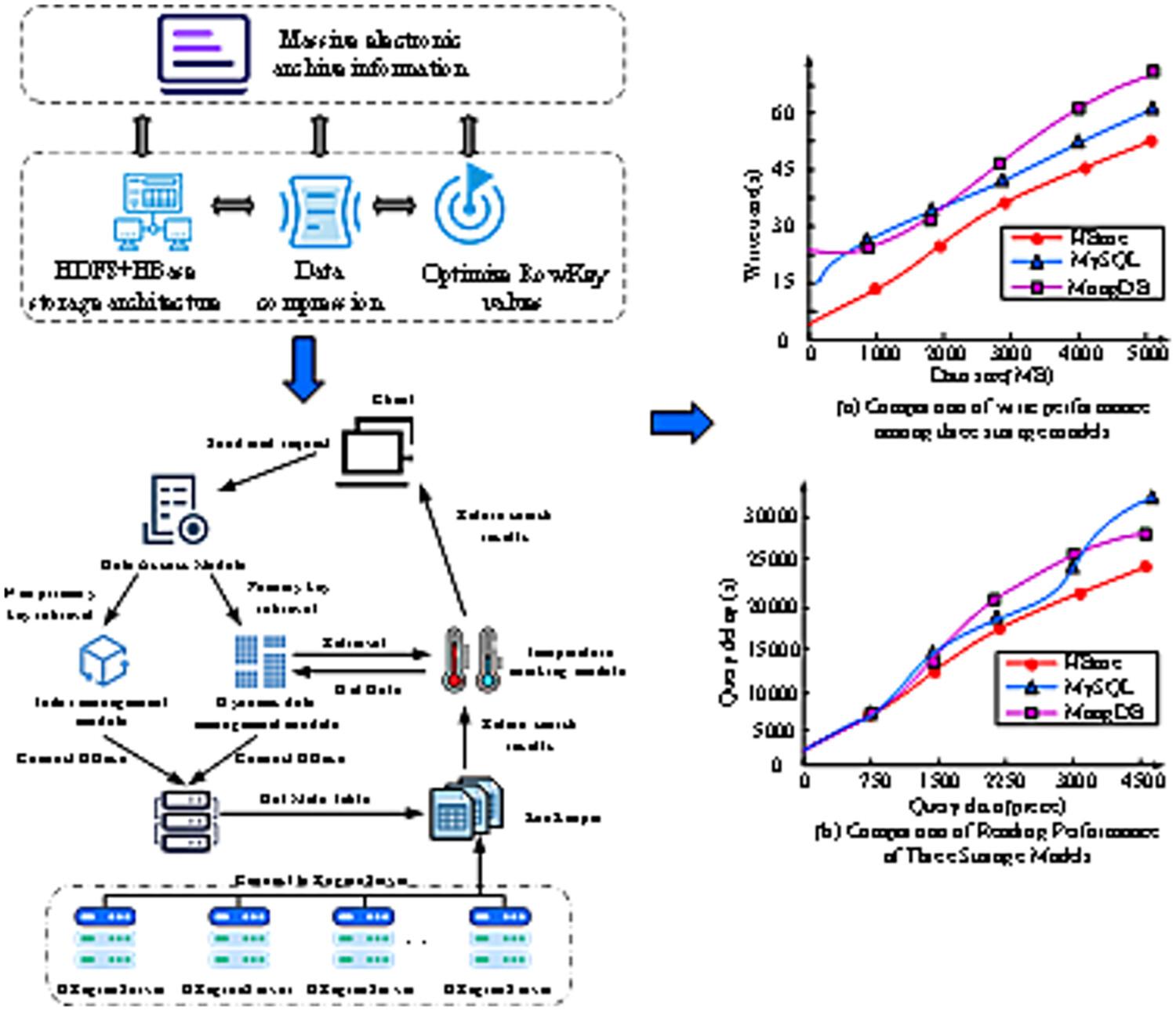
The acceleration of the digitalization process in enterprise and university education management has generated a massive amount of electronic archive data. In order to improve the intelligence, storage quality, and efficiency of electronic records management and achieve efficient storage and fast retrieval of data storage models, this study proposes a massive data storage model based on HBase and its retrieval optimization scheme design. In addition, HDFS is introduced to construct a two-level storage structure and optimize values to improve the scalability and load balancing of HBase, and the retrieval efficiency of the HBase storage model is improved through SL-TCR and BF filters. The results indicated that HDFS could automatically recover data after node, network partition, and NameNode failures. The write time of HBase was 56 s, which was 132 and 246 s less than Cassandra and CockroachDB. The query latency was reduced by 23% and 32%, and the query time was reduced by 9988.51 ms, demonstrating high reliability and efficiency. The delay of BF-SL-TCL was 1379.28 s after 1000 searches, which was 224.78 and 212.74 s less than SL-TCL and Blockchain Retrieval Acceleration and reduced the delay under high search times. In summary, this storage model has obvious advantages in storing massive amounts of electronic archive data and has high security and retrieval efficiency, which provides important reference for the design of storage models for future electronic archive management. The storage model designed by the research institute has obvious advantages in storing massive electronic archive data, solving the problem of lack of scalability in electronic archive management when facing massive data, and has high security and retrieval efficiency. It has important reference for the design of storage models for future electronic archive management.
期刊介绍:
Modern computer networks and communication systems are increasing in size, scope, and heterogeneity. The promise of a single end-to-end technology has not been realized and likely never will occur. The decreasing cost of bandwidth is increasing the possible applications of computer networks and communication systems to entirely new domains. Problems in integrating heterogeneous wired and wireless technologies, ensuring security and quality of service, and reliably operating large-scale systems including the inclusion of cloud computing have all emerged as important topics. The one constant is the need for network management. Challenges in network management have never been greater than they are today. The International Journal of Network Management is the forum for researchers, developers, and practitioners in network management to present their work to an international audience. The journal is dedicated to the dissemination of information, which will enable improved management, operation, and maintenance of computer networks and communication systems. The journal is peer reviewed and publishes original papers (both theoretical and experimental) by leading researchers, practitioners, and consultants from universities, research laboratories, and companies around the world. Issues with thematic or guest-edited special topics typically occur several times per year. Topic areas for the journal are largely defined by the taxonomy for network and service management developed by IFIP WG6.6, together with IEEE-CNOM, the IRTF-NMRG and the Emanics Network of Excellence.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


