A lightweight depth completion network with spatial efficient fusion
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Depth completion is a low-level task rebuilding the dense depth from a sparse set of measurements from LiDAR sensors and corresponding RGB images. Current state-of-the-art depth completion methods used complicated network designs with much computational cost increase, which is incompatible with the realistic-scenario limited computational environment. In this paper, we explore a lightweight and efficient depth completion model named Light-SEF. Light-SEF is a two-stage framework that introduces local fusion and global fusion modules to extract and fuse local and global information in the sparse LiDAR data and RGB images. We also propose a unit convolutional structure named spatial efficient block (SEB), which has a lightweight design and extracts spatial features efficiently. As the unit block of the whole network, SEB is much more cost-efficient compared to the baseline design. Experimental results on the KITTI benchmark demonstrate that our Light-SEF achieves significant declines in computational cost (about 53% parameters, 50% FLOPs & MACs, and 36% running time) while showing competitive results compared to state-of-the-art methods.
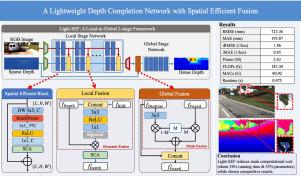
具有空间高效融合功能的轻量级深度补全网络
深度补全是一项从激光雷达传感器的稀疏测量数据集和相应的 RGB 图像中重建密集深度的底层任务。目前最先进的深度补全方法采用复杂的网络设计,计算成本大幅增加,不符合现实场景有限的计算环境。在本文中,我们探索了一种名为 Light-SEF 的轻量级高效深度补全模型。Light-SEF 是一个两阶段框架,引入了局部融合和全局融合模块,以提取和融合稀疏激光雷达数据和 RGB 图像中的局部和全局信息。我们还提出了一种名为 "空间高效块(SEB)"的单元卷积结构,该结构设计轻巧,能高效提取空间特征。作为整个网络的单元块,SEB 与基线设计相比更具成本效益。在 KITTI 基准上的实验结果表明,与最先进的方法相比,我们的 Light-SEF 实现了计算成本的显著下降(约 53% 的参数、50% 的 FLOPs & MACs 和 36% 的运行时间),同时显示出具有竞争力的结果。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


