Multimodal language and graph learning of adsorption configuration in catalysis
IF 18.8
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
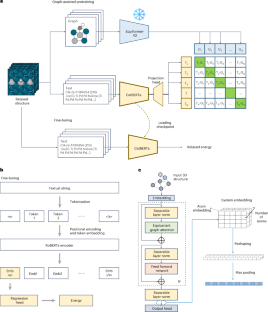
Adsorption energy is a reactivity descriptor that must be accurately predicted for effective machine learning application in catalyst screening. This process involves finding the lowest energy among different adsorption configurations on a catalytic surface, which often have very similar energies. Although graph neural networks have shown great success in computing the energy of catalyst systems, they rely heavily on atomic spatial coordinates. By contrast, transformer-based language models can directly use human-readable text inputs, potentially bypassing the need for detailed atomic positions or topology; however, these language models often struggle with accurately predicting the energy of adsorption configurations. Our study improves the predictive language model by aligning its latent space with well-established graph neural networks through a self-supervised process called graph-assisted pretraining. This method reduces the mean absolute error of energy prediction for adsorption configurations by 7.4–9.8%, redirecting the model’s attention towards adsorption configuration. Building on this, we propose using generative large language models to create text inputs for the predictive model without relying on exact atomic positions. This demonstrates a potential use case of language models in energy prediction without detailed geometric information. Ock and colleagues explore predictive and generative language models for improving adsorption energy prediction in catalysis without relying on exact atomic positions. The method involves aligning a language model’s latent space with graph neural networks using graph-assisted pretraining.

催化中吸附构型的多模态语言和图式学习
吸附能是一种反应性描述符,必须对其进行准确预测,才能有效地将机器学习应用于催化剂筛选。这一过程涉及在催化剂表面的不同吸附构型中寻找能量最低的构型,而这些构型通常具有非常相似的能量。虽然图神经网络在计算催化剂系统能量方面取得了巨大成功,但它们在很大程度上依赖于原子空间坐标。相比之下,基于变换器的语言模型可以直接使用人类可读的文本输入,从而有可能绕过对详细原子位置或拓扑结构的需求;然而,这些语言模型在准确预测吸附构型的能量方面往往力不从心。我们的研究通过一种称为图辅助预训练的自我监督过程,将其潜在空间与成熟的图神经网络相匹配,从而改进了预测性语言模型。这种方法可将吸附构型能量预测的平均绝对误差降低 7.4-9.8%,从而将模型的注意力重新引向吸附构型。在此基础上,我们建议使用生成式大型语言模型为预测模型创建文本输入,而无需依赖精确的原子位置。这展示了在没有详细几何信息的情况下,语言模型在能量预测中的潜在用例。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


