Taymaz Akan, Sait Alp, Md Shenuarin Bhuiyan, Tarek Helmy, A Wayne Orr, Md Mostafizur Rahman Bhuiyan, Steven A Conrad, John A Vanchiere, Christopher G Kevil, Mohammad Alfrad Nobel Bhuiyan
{"title":"ViViEchoformer: Deep Video Regressor Predicting Ejection Fraction.","authors":"Taymaz Akan, Sait Alp, Md Shenuarin Bhuiyan, Tarek Helmy, A Wayne Orr, Md Mostafizur Rahman Bhuiyan, Steven A Conrad, John A Vanchiere, Christopher G Kevil, Mohammad Alfrad Nobel Bhuiyan","doi":"10.1007/s10278-024-01336-y","DOIUrl":null,"url":null,"abstract":"<p><p>Heart disease is the leading cause of death worldwide, and cardiac function as measured by ejection fraction (EF) is an important determinant of outcomes, making accurate measurement a critical parameter in PT evaluation. Echocardiograms are commonly used for measuring EF, but human interpretation has limitations in terms of intra- and inter-observer (or reader) variance. Deep learning (DL) has driven a resurgence in machine learning, leading to advancements in medical applications. We introduce the ViViEchoformer DL approach, which uses a video vision transformer to directly regress the left ventricular function (LVEF) from echocardiogram videos. The study used a dataset of 10,030 apical-4-chamber echocardiography videos from patients at Stanford University Hospital. The model accurately captures spatial information and preserves inter-frame relationships by extracting spatiotemporal tokens from video input, allowing for accurate, fully automatic EF predictions that aid human assessment and analysis. The ViViEchoformer's prediction of ejection fraction has a mean absolute error of 6.14%, a root mean squared error of 8.4%, a mean squared log error of 0.04, and an <math> <msup><mrow><mi>R</mi></mrow> <mn>2</mn></msup> </math> of 0.55. ViViEchoformer predicted heart failure with reduced ejection fraction (HFrEF) with an area under the curve of 0.83 and a classification accuracy of 87 using a standard threshold of less than 50% ejection fraction. Our video-based method provides precise left ventricular function quantification, offering a reliable alternative to human evaluation and establishing a fundamental basis for echocardiogram interpretation.</p>","PeriodicalId":516858,"journal":{"name":"Journal of imaging informatics in medicine","volume":" ","pages":"2041-2052"},"PeriodicalIF":0.0000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12343374/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of imaging informatics in medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10278-024-01336-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/25 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
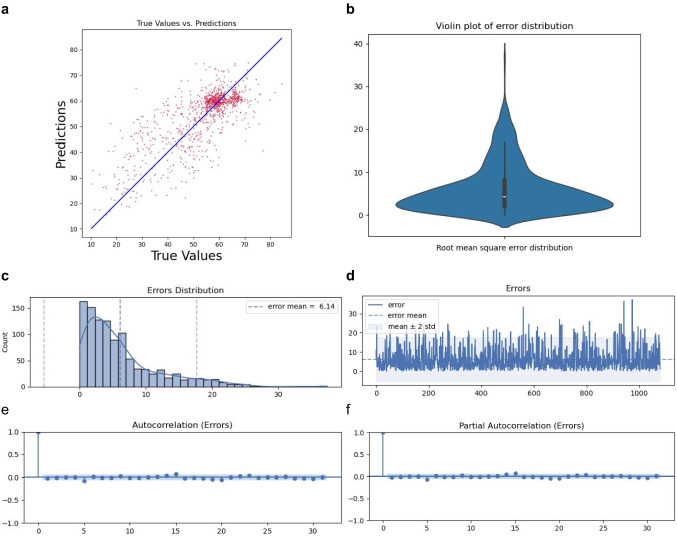
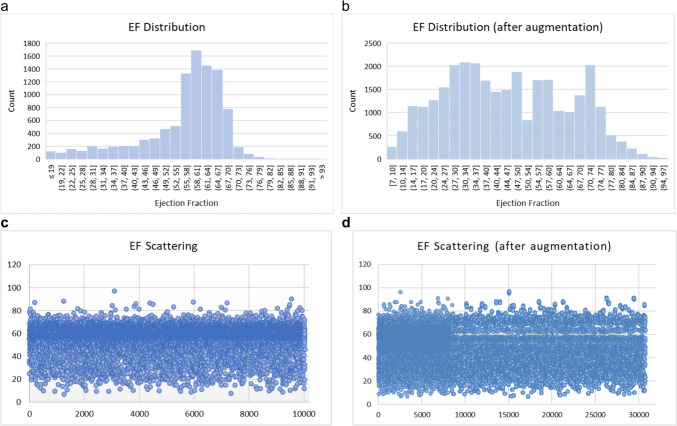
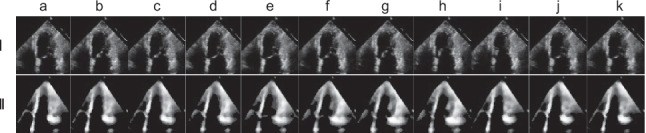
Heart disease is the leading cause of death worldwide, and cardiac function as measured by ejection fraction (EF) is an important determinant of outcomes, making accurate measurement a critical parameter in PT evaluation. Echocardiograms are commonly used for measuring EF, but human interpretation has limitations in terms of intra- and inter-observer (or reader) variance. Deep learning (DL) has driven a resurgence in machine learning, leading to advancements in medical applications. We introduce the ViViEchoformer DL approach, which uses a video vision transformer to directly regress the left ventricular function (LVEF) from echocardiogram videos. The study used a dataset of 10,030 apical-4-chamber echocardiography videos from patients at Stanford University Hospital. The model accurately captures spatial information and preserves inter-frame relationships by extracting spatiotemporal tokens from video input, allowing for accurate, fully automatic EF predictions that aid human assessment and analysis. The ViViEchoformer's prediction of ejection fraction has a mean absolute error of 6.14%, a root mean squared error of 8.4%, a mean squared log error of 0.04, and an of 0.55. ViViEchoformer predicted heart failure with reduced ejection fraction (HFrEF) with an area under the curve of 0.83 and a classification accuracy of 87 using a standard threshold of less than 50% ejection fraction. Our video-based method provides precise left ventricular function quantification, offering a reliable alternative to human evaluation and establishing a fundamental basis for echocardiogram interpretation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


