Classifying Tumor Reportability Status From Unstructured Electronic Pathology Reports Using Language Models in a Population-Based Cancer Registry Setting.
Lovedeep Gondara, Jonathan Simkin, Gregory Arbour, Shebnum Devji, Raymond Ng
{"title":"Classifying Tumor Reportability Status From Unstructured Electronic Pathology Reports Using Language Models in a Population-Based Cancer Registry Setting.","authors":"Lovedeep Gondara, Jonathan Simkin, Gregory Arbour, Shebnum Devji, Raymond Ng","doi":"10.1200/CCI.24.00110","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Population-based cancer registries (PBCRs) collect data on all new cancer diagnoses in a defined population. Data are sourced from pathology reports, and the PBCRs rely on manual and rule-based solutions. This study presents a state-of-the-art natural language processing (NLP) pipeline, built by fine-tuning pretrained language models (LMs). The pipeline is deployed at the British Columbia Cancer Registry (BCCR) to detect reportable tumors from a population-based feed of electronic pathology.</p><p><strong>Methods: </strong>We fine-tune two publicly available LMs, GatorTron and BlueBERT, which are pretrained on clinical text. Fine-tuning is done using BCCR's pathology reports. For the final decision making, we combine both models' output using an OR approach. The fine-tuning data set consisted of 40,000 reports from the diagnosis year of 2021, and the test data sets consisted of 10,000 reports from the diagnosis year 2021, 20,000 reports from diagnosis year 2022, and 400 reports from diagnosis year 2023.</p><p><strong>Results: </strong>The retrospective evaluation of our proposed approach showed boosted reportable accuracy, maintaining the true reportable threshold of 98%.</p><p><strong>Conclusion: </strong>Disadvantages of rule-based NLP in cancer surveillance include manual effort in rule design and sensitivity to language change. Deep learning approaches demonstrate superior performance in classification. PBCRs distinguish reportability status of incoming electronic cancer pathology reports. Deep learning methods provide significant advantages over rule-based NLP.</p>","PeriodicalId":51626,"journal":{"name":"JCO Clinical Cancer Informatics","volume":"8 ","pages":"e2400110"},"PeriodicalIF":2.8000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11593994/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JCO Clinical Cancer Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1200/CCI.24.00110","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/19 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
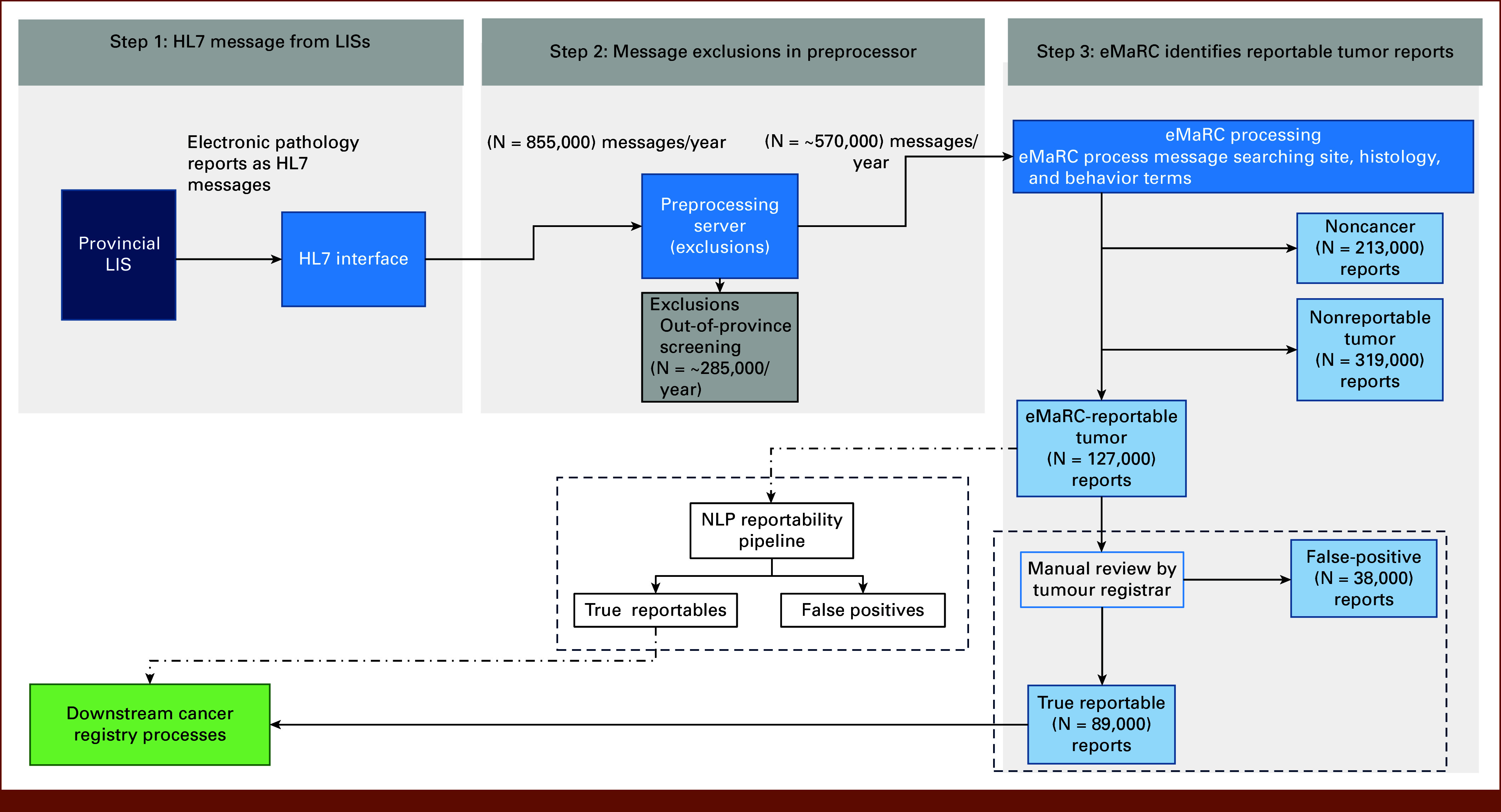
Purpose: Population-based cancer registries (PBCRs) collect data on all new cancer diagnoses in a defined population. Data are sourced from pathology reports, and the PBCRs rely on manual and rule-based solutions. This study presents a state-of-the-art natural language processing (NLP) pipeline, built by fine-tuning pretrained language models (LMs). The pipeline is deployed at the British Columbia Cancer Registry (BCCR) to detect reportable tumors from a population-based feed of electronic pathology.
Methods: We fine-tune two publicly available LMs, GatorTron and BlueBERT, which are pretrained on clinical text. Fine-tuning is done using BCCR's pathology reports. For the final decision making, we combine both models' output using an OR approach. The fine-tuning data set consisted of 40,000 reports from the diagnosis year of 2021, and the test data sets consisted of 10,000 reports from the diagnosis year 2021, 20,000 reports from diagnosis year 2022, and 400 reports from diagnosis year 2023.
Results: The retrospective evaluation of our proposed approach showed boosted reportable accuracy, maintaining the true reportable threshold of 98%.
Conclusion: Disadvantages of rule-based NLP in cancer surveillance include manual effort in rule design and sensitivity to language change. Deep learning approaches demonstrate superior performance in classification. PBCRs distinguish reportability status of incoming electronic cancer pathology reports. Deep learning methods provide significant advantages over rule-based NLP.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


