A strategy for cost-effective large language model use at health system-scale
IF 12.4
1区 医学
Q1 HEALTH CARE SCIENCES & SERVICES
引用次数: 0
Abstract
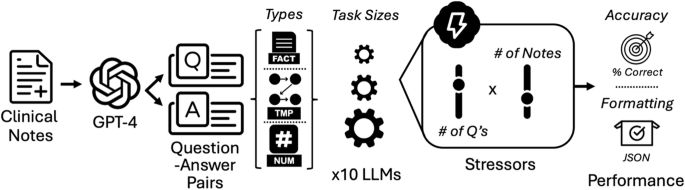
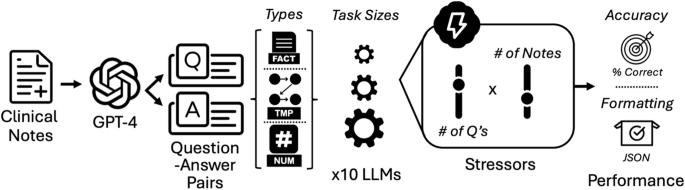
Large language models (LLMs) can optimize clinical workflows; however, the economic and computational challenges of their utilization at the health system scale are underexplored. We evaluated how concatenating queries with multiple clinical notes and tasks simultaneously affects model performance under increasing computational loads. We assessed ten LLMs of different capacities and sizes utilizing real-world patient data. We conducted >300,000 experiments of various task sizes and configurations, measuring accuracy in question-answering and the ability to properly format outputs. Performance deteriorated as the number of questions and notes increased. High-capacity models, like Llama-3–70b, had low failure rates and high accuracies. GPT-4-turbo-128k was similarly resilient across task burdens, but performance deteriorated after 50 tasks at large prompt sizes. After addressing mitigable failures, these two models can concatenate up to 50 simultaneous tasks effectively, with validation on a public medical question-answering dataset. An economic analysis demonstrated up to a 17-fold cost reduction at 50 tasks using concatenation. These results identify the limits of LLMs for effective utilization and highlight avenues for cost-efficiency at the enterprise scale.
在医疗系统范围内使用具有成本效益的大型语言模型的策略
大型语言模型(LLMs)可以优化临床工作流程;然而,在医疗系统范围内使用这些模型所面临的经济和计算挑战还未得到充分探索。我们评估了在计算负荷不断增加的情况下,同时连接多个临床笔记和任务的查询对模型性能的影响。我们利用真实世界的患者数据评估了十种不同容量和规模的 LLM。我们进行了 300,000 次不同任务规模和配置的实验,衡量了问题解答的准确性和正确格式化输出的能力。随着问题和笔记数量的增加,性能也在下降。大容量模型,如 Llama-3-70b ,故障率低,准确率高。GPT-4-turbo-128k 在任务繁重的情况下也具有类似的适应能力,但在 50 个任务之后,提示大小变大,性能也随之下降。在解决了可缓解的故障后,这两个模型可以有效地同时连接多达 50 个任务,并在一个公共医疗问题解答数据集上进行了验证。经济分析表明,在 50 个任务的情况下,使用串联技术最多可将成本降低 17 倍。这些结果确定了有效利用 LLM 的局限性,并强调了在企业规模实现成本效益的途径。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

NPJ Digital Medicine
Multiple-
CiteScore
25.10
自引率
3.30%
发文量
170
审稿时长
15 weeks
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


