Mitigating gradient conflicts via expert squads in multi-task learning
IF 5.5
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
The foundation of multi-task learning lies in the collaboration and interaction among tasks. However, in numerous real-world scenarios, certain tasks usually necessitate distinct, specialized knowledge. The mixing of these different task-specific knowledge often results in gradient conflicts during the optimization process, posing a significant challenge in the design of effective multi-task learning systems. This study proposes a straightforward yet effective multi-task learning framework that employs groups of expert networks to decouple the learning of task-specific knowledge and mitigate such gradient conflicts. Specifically, this approach partitions the feature channels into task-specific and shared components. The task-specific subsets are processed by dedicated experts to distill specialized knowledge. The shared features are captured by a point-wise aggregation layer from the whole outputs of all experts, demonstrating superior performance in capturing inter-task interactions. By considering both task-specific knowledge and shared features, the proposed approach exhibits superior performance in multi-task learning. Extensive experiments conducted on the PASCAL-Context and NYUD-v2 datasets have demonstrated the superiority of the proposed approach compared to other state-of-the-art methods. Furthermore, a benchmark dataset for multi-task learning in underwater scenarios has been developed, encompassing object detection and underwater image enhancement tasks. Comprehensive experiments on this dataset consistently validate the effectiveness of the proposed multi-task learning strategy. The source code is available at https://github.com/chenjie04/Multi-Task-Learning-PyTorch.
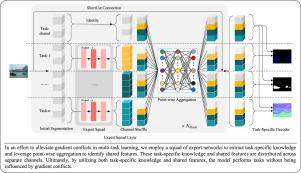
通过多任务学习中的专家小组缓解梯度冲突
多任务学习的基础在于任务之间的协作和互动。然而,在现实世界的众多场景中,某些任务通常需要不同的专业知识。在优化过程中,这些不同任务的特定知识混合在一起往往会导致梯度冲突,这给设计有效的多任务学习系统带来了巨大挑战。本研究提出了一种简单而有效的多任务学习框架,利用专家网络组来分离特定任务知识的学习,并缓解这种梯度冲突。具体来说,这种方法将特征通道分为特定任务和共享部分。特定任务子集由专门的专家处理,以提炼专业知识。共享特征则由来自所有专家的整体输出的点式聚合层捕获,在捕获任务间交互方面表现出卓越的性能。通过同时考虑特定任务知识和共享特征,所提出的方法在多任务学习中表现出了卓越的性能。在 PASCAL-Context 和 NYUD-v2 数据集上进行的大量实验证明,与其他最先进的方法相比,所提出的方法具有更高的性能。此外,还开发了水下场景多任务学习的基准数据集,其中包括物体检测和水下图像增强任务。在该数据集上进行的综合实验一致验证了所提出的多任务学习策略的有效性。源代码见 https://github.com/chenjie04/Multi-Task-Learning-PyTorch。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Neurocomputing
工程技术-计算机:人工智能
CiteScore
13.10
自引率
10.00%
发文量
1382
审稿时长
70 days
期刊介绍:
Neurocomputing publishes articles describing recent fundamental contributions in the field of neurocomputing. Neurocomputing theory, practice and applications are the essential topics being covered.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


