The pupil outdoes the master: Imperfect demonstration-assisted trust region jamming policy optimization against frequency-hopping spread spectrum
IF 4.3
3区 计算机科学
Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
Abstract
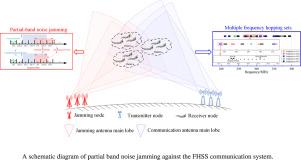
Jamming decision-making is a pivotal component of modern electromagnetic warfare, wherein recent years have witnessed the extensive application of deep reinforcement learning techniques to enhance the autonomy and intelligence of wireless communication jamming decisions. However, existing researches heavily rely on manually designed customized jamming reward functions, leading to significant consumption of human and computational resources. To this end, under the premise of obviating designing task-customized reward functions, we propose a jamming policy optimization method that learns from imperfect demonstrations to effectively address the complex and high-dimensional jamming resource allocation problem against frequency hopping spread spectrum (FHSS) communication systems. To achieve this, a policy network is meticulously architected to consecutively ascertain jamming schemes for each jamming node, facilitating the construction of the dynamic transition within the Markov decision process. Subsequently, anchored in the dual-trust region concept, we design policy improvement and policy adversarial imitation phases. During the policy improvement phase, the trust region policy optimization method is utilized to refine the policy, while the policy adversarial imitation phase employs adversarial training to guide policy exploration using information embedded in demonstrations. Extensive simulation results indicate that our proposed method can approximate the optimal jamming performance trained under customized reward functions, even with rough binary reward settings, and also significantly surpass demonstration performance.
徒弟胜过师傅针对跳频扩频的不完美演示辅助信任区域干扰策略优化
干扰决策是现代电磁战的关键组成部分,近年来,人们广泛应用深度强化学习技术来增强无线通信干扰决策的自主性和智能性。然而,现有研究严重依赖人工设计的定制干扰奖励函数,导致大量人力和计算资源的消耗。为此,在避免设计任务定制奖励函数的前提下,我们提出了一种干扰策略优化方法,该方法可从不完善的演示中学习,从而有效解决针对跳频扩频(FHSS)通信系统的复杂、高维干扰资源分配问题。为此,我们精心构建了一个策略网络,以连续确定每个干扰节点的干扰方案,从而促进马尔可夫决策过程中动态转换的构建。随后,我们以双信任区域概念为基础,设计了策略改进和策略对抗模仿阶段。在策略改进阶段,我们利用信任区域策略优化方法来完善策略;而在策略对抗模仿阶段,我们利用对抗训练来引导策略探索,并将信息嵌入到演示中。广泛的仿真结果表明,我们提出的方法即使在粗略的二进制奖励设置下,也能逼近在定制奖励函数下训练出的最佳干扰性能,而且还能显著超越演示性能。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computer Communications
工程技术-电信学
CiteScore
14.10
自引率
5.00%
发文量
397
审稿时长
66 days
期刊介绍:
Computer and Communications networks are key infrastructures of the information society with high socio-economic value as they contribute to the correct operations of many critical services (from healthcare to finance and transportation). Internet is the core of today''s computer-communication infrastructures. This has transformed the Internet, from a robust network for data transfer between computers, to a global, content-rich, communication and information system where contents are increasingly generated by the users, and distributed according to human social relations. Next-generation network technologies, architectures and protocols are therefore required to overcome the limitations of the legacy Internet and add new capabilities and services. The future Internet should be ubiquitous, secure, resilient, and closer to human communication paradigms.
Computer Communications is a peer-reviewed international journal that publishes high-quality scientific articles (both theory and practice) and survey papers covering all aspects of future computer communication networks (on all layers, except the physical layer), with a special attention to the evolution of the Internet architecture, protocols, services, and applications.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


