{"title":"ConCPDP: A Cross-Project Defect Prediction Method Integrating Contrastive Pretraining and Category Boundary Adjustment","authors":"Hengjie Song, Yufei Pan, Feng Guo, Xue Zhang, Le Ma, Siyu Jiang","doi":"10.1049/2024/5102699","DOIUrl":null,"url":null,"abstract":"<p>Software defect prediction (SDP) is a crucial phase preceding the launch of software products. Cross-project defect prediction (CPDP) is introduced for the anticipation of defects in novel projects lacking defect labels. CPDP can use defect information of mature projects to speed up defect prediction for new projects. So that developers can quickly get the defect information of the new project, so that they can test the software project pertinently. At present, the predominant approaches in CPDP rely on deep learning, and the performance of the ultimate model is notably affected by the quality of the training dataset. However, the dataset of CPDP not only has few samples but also has almost no label information in new projects, which makes the general deep-learning-based CPDP model not ideal. In addition, most of the current CPDP models do not fully consider the enrichment of classification boundary samples after cross-domain, leading to suboptimal predictive capabilities of the model. To overcome these obstacles, we present contrastive learning pretraining for CPDP (ConCPDP), a CPDP method integrating contrastive pretraining and category boundary adjustment. We first perform data augmentation on the source and target domain code files and then extract the enhanced data as an abstract syntax tree (AST). The AST is then transformed into an integer sequence using specific mapping rules, serving as input for the subsequent neural network. A neural network based on bidirectional long short-term memory (Bi-LSTM) will receive an integer sequence and output a feature vector. Then, the feature vectors are input into the contrastive module to optimise the feature extraction network. The pretrained feature extractor can be fine-tuned by the maximum mean discrepancy (MMD) between the feature distribution of the source domain and the target domain and the binary classification loss on the source domain. This paper conducts a large number of experiments on the PROMISE dataset, which is commonly used for CPDP, to validate ConCPDP’s efficacy, achieving superior results in terms of <i>F</i><sub>1</sub> measure, area under curve (AUC), and Matthew’s correlation coefficient (MCC).</p>","PeriodicalId":50378,"journal":{"name":"IET Software","volume":"2024 1","pages":""},"PeriodicalIF":1.3000,"publicationDate":"2024-11-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/2024/5102699","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Software","FirstCategoryId":"94","ListUrlMain":"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/2024/5102699","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
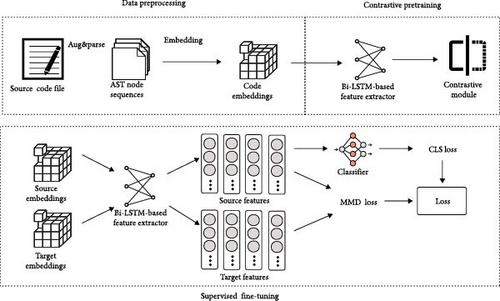
Software defect prediction (SDP) is a crucial phase preceding the launch of software products. Cross-project defect prediction (CPDP) is introduced for the anticipation of defects in novel projects lacking defect labels. CPDP can use defect information of mature projects to speed up defect prediction for new projects. So that developers can quickly get the defect information of the new project, so that they can test the software project pertinently. At present, the predominant approaches in CPDP rely on deep learning, and the performance of the ultimate model is notably affected by the quality of the training dataset. However, the dataset of CPDP not only has few samples but also has almost no label information in new projects, which makes the general deep-learning-based CPDP model not ideal. In addition, most of the current CPDP models do not fully consider the enrichment of classification boundary samples after cross-domain, leading to suboptimal predictive capabilities of the model. To overcome these obstacles, we present contrastive learning pretraining for CPDP (ConCPDP), a CPDP method integrating contrastive pretraining and category boundary adjustment. We first perform data augmentation on the source and target domain code files and then extract the enhanced data as an abstract syntax tree (AST). The AST is then transformed into an integer sequence using specific mapping rules, serving as input for the subsequent neural network. A neural network based on bidirectional long short-term memory (Bi-LSTM) will receive an integer sequence and output a feature vector. Then, the feature vectors are input into the contrastive module to optimise the feature extraction network. The pretrained feature extractor can be fine-tuned by the maximum mean discrepancy (MMD) between the feature distribution of the source domain and the target domain and the binary classification loss on the source domain. This paper conducts a large number of experiments on the PROMISE dataset, which is commonly used for CPDP, to validate ConCPDP’s efficacy, achieving superior results in terms of F1 measure, area under curve (AUC), and Matthew’s correlation coefficient (MCC).
期刊介绍:
IET Software publishes papers on all aspects of the software lifecycle, including design, development, implementation and maintenance. The focus of the journal is on the methods used to develop and maintain software, and their practical application.
Authors are especially encouraged to submit papers on the following topics, although papers on all aspects of software engineering are welcome:
Software and systems requirements engineering
Formal methods, design methods, practice and experience
Software architecture, aspect and object orientation, reuse and re-engineering
Testing, verification and validation techniques
Software dependability and measurement
Human systems engineering and human-computer interaction
Knowledge engineering; expert and knowledge-based systems, intelligent agents
Information systems engineering
Application of software engineering in industry and commerce
Software engineering technology transfer
Management of software development
Theoretical aspects of software development
Machine learning
Big data and big code
Cloud computing
Current Special Issue. Call for papers:
Knowledge Discovery for Software Development - https://digital-library.theiet.org/files/IET_SEN_CFP_KDSD.pdf
Big Data Analytics for Sustainable Software Development - https://digital-library.theiet.org/files/IET_SEN_CFP_BDASSD.pdf


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


