Ethar Alzaid, Gabriele Pergola, Harriet Evans, David Snead, Fayyaz Minhas
{"title":"Large multimodal model-based standardisation of pathology reports with confidence and its prognostic significance","authors":"Ethar Alzaid, Gabriele Pergola, Harriet Evans, David Snead, Fayyaz Minhas","doi":"10.1002/2056-4538.70010","DOIUrl":null,"url":null,"abstract":"<p>Despite the existence of established standards and guidelines for pathology reporting, many pathology reports are still written in unstructured free text. Extracting information from these reports and formatting it according to a standard is crucial for consistent interpretation. Automated information extraction from unstructured pathology reports is a challenging task, as it requires accurately interpreting medical terminologies and context-dependent details. In this work, we present a practical approach for automatically extracting information from unstructured pathology reports or scanned paper reports utilising a large multimodal model. This framework uses context-aware prompting strategies to extract values of individual fields, such as grade, size, etc. from pathology reports. A unique feature of the proposed approach is that it assigns a confidence value indicating the correctness of the model's extraction for each field and generates a structured report in line with national pathology guidelines in human and machine-readable formats. We have analysed the extraction performance in terms of accuracy and kappa scores, and the quality of the confidence scores assigned by the model. We have also evaluated the prognostic value of the extracted fields and feature embeddings of the raw text. Results showed that the model can accurately extract information with an accuracy and kappa score up to 0.99 and 0.98, respectively. Our results indicate that confidence scores are an effective indicator of the correctness of the extracted information achieving an area under the receiver operating characteristic curve up to 0.93 thus enabling automatic flagging of extraction errors. Our analysis further reveals that, as expected, information extracted from pathology reports is highly prognostically relevant. The framework demo is available at: https://labieb.dcs.warwick.ac.uk/. Information extracted from pathology reports of colorectal cancer cases in the cancer genome atlas using the proposed approach and its code are available at: https://github.com/EtharZaid/Labieb.</p>","PeriodicalId":48612,"journal":{"name":"Journal of Pathology Clinical Research","volume":"10 6","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2024-11-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/2056-4538.70010","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Pathology Clinical Research","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/2056-4538.70010","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PATHOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
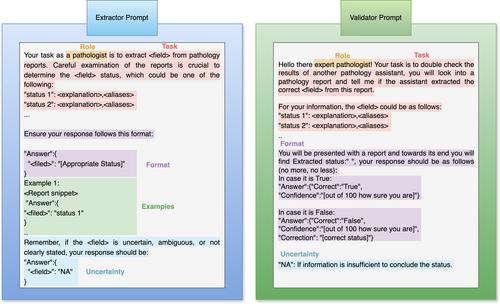
Despite the existence of established standards and guidelines for pathology reporting, many pathology reports are still written in unstructured free text. Extracting information from these reports and formatting it according to a standard is crucial for consistent interpretation. Automated information extraction from unstructured pathology reports is a challenging task, as it requires accurately interpreting medical terminologies and context-dependent details. In this work, we present a practical approach for automatically extracting information from unstructured pathology reports or scanned paper reports utilising a large multimodal model. This framework uses context-aware prompting strategies to extract values of individual fields, such as grade, size, etc. from pathology reports. A unique feature of the proposed approach is that it assigns a confidence value indicating the correctness of the model's extraction for each field and generates a structured report in line with national pathology guidelines in human and machine-readable formats. We have analysed the extraction performance in terms of accuracy and kappa scores, and the quality of the confidence scores assigned by the model. We have also evaluated the prognostic value of the extracted fields and feature embeddings of the raw text. Results showed that the model can accurately extract information with an accuracy and kappa score up to 0.99 and 0.98, respectively. Our results indicate that confidence scores are an effective indicator of the correctness of the extracted information achieving an area under the receiver operating characteristic curve up to 0.93 thus enabling automatic flagging of extraction errors. Our analysis further reveals that, as expected, information extracted from pathology reports is highly prognostically relevant. The framework demo is available at: https://labieb.dcs.warwick.ac.uk/. Information extracted from pathology reports of colorectal cancer cases in the cancer genome atlas using the proposed approach and its code are available at: https://github.com/EtharZaid/Labieb.
期刊介绍:
The Journal of Pathology: Clinical Research and The Journal of Pathology serve as translational bridges between basic biomedical science and clinical medicine with particular emphasis on, but not restricted to, tissue based studies.
The focus of The Journal of Pathology: Clinical Research is the publication of studies that illuminate the clinical relevance of research in the broad area of the study of disease. Appropriately powered and validated studies with novel diagnostic, prognostic and predictive significance, and biomarker discover and validation, will be welcomed. Studies with a predominantly mechanistic basis will be more appropriate for the companion Journal of Pathology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


