MultiADE: A Multi-domain benchmark for Adverse Drug Event extraction
IF 4
2区 医学
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
Objective:
Active adverse event surveillance monitors Adverse Drug Events (ADE) from different data sources, such as electronic health records, medical literature, social media and search engine logs. Over the years, many datasets have been created, and shared tasks have been organised to facilitate active adverse event surveillance. However, most – if not all – datasets or shared tasks focus on extracting ADEs from a particular type of text. Domain generalisation – the ability of a machine learning model to perform well on new, unseen domains (text types) – is under-explored. Given the rapid advancements in natural language processing, one unanswered question is how far we are from having a single ADE extraction model that is effective on various types of text, such as scientific literature and social media posts.
Methods:
We contribute to answering this question by building a multi-domain benchmark for adverse drug event extraction, which we named MultiADE. The new benchmark comprises several existing datasets sampled from different text types and our newly created dataset—CADECv2, which is an extension of CADEC (Karimi et al., 2015), covering online posts regarding more diverse drugs than CADEC. Our new dataset is carefully annotated by human annotators following detailed annotation guidelines.
Conclusion:
Our benchmark results show that the generalisation of the trained models is far from perfect, making it infeasible to be deployed to process different types of text. In addition, although intermediate transfer learning is a promising approach to utilising existing resources, further investigation is needed on methods of domain adaptation, particularly cost-effective methods to select useful training instances.
The newly created CADECv2 and the scripts for building the benchmark are publicly available at CSIRO’s Data Portal (https://data.csiro.au/collection/csiro:62387). These resources enable the research community to further information extraction, leading to more effective active adverse drug event surveillance.
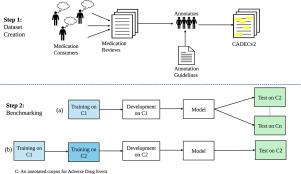
MultiADE:药物不良事件提取的多领域基准。
目的:主动不良事件监测从电子健康记录、医学文献、社交媒体和搜索引擎日志等不同数据源监测药物不良事件 (ADE)。多年来,人们创建了许多数据集,并组织了共享任务,以促进主动不良事件监测。然而,大多数(如果不是全部的话)数据集或共享任务都侧重于从特定类型的文本中提取 ADE。领域泛化--机器学习模型在新的、未见过的领域(文本类型)中表现良好的能力--还未得到充分探索。鉴于自然语言处理技术的飞速发展,一个悬而未决的问题是,我们离建立一个能在科学文献和社交媒体帖子等各种类型文本中有效使用的单一 ADE 提取模型还有多远:我们建立了一个多领域药物不良事件提取基准,并将其命名为 MultiADE,从而为回答这个问题做出了贡献。新基准包括从不同文本类型中采样的几个现有数据集和我们新创建的数据集--CADECv2,它是 CADEC(Karimi 等人,2015 年)的扩展,涵盖了比 CADEC 更多不同药物的在线帖子。我们的新数据集由人类注释者按照详细的注释指南进行仔细注释:我们的基准结果表明,训练模型的泛化能力远非完美,因此无法用于处理不同类型的文本。此外,尽管中间转移学习是一种很有前途的利用现有资源的方法,但还需要进一步研究领域适应方法,特别是选择有用的训练实例的经济有效的方法。新创建的 CADECv2 和用于构建基准的脚本可在 CSIRO 的数据门户网站 (https://data.csiro.au/collection/csiro:62387) 上公开获取。这些资源使研究界能够进一步提取信息,从而更有效地开展药物不良事件主动监测。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Biomedical Informatics
医学-计算机:跨学科应用
CiteScore
8.90
自引率
6.70%
发文量
243
审稿时长
32 days
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


