Cross-Modal self-supervised vision language pre-training with multiple objectives for medical visual question answering
IF 4
2区 医学
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
Medical Visual Question Answering (VQA) is a task that aims to provide answers to questions about medical images, which utilizes both visual and textual information in the reasoning process. The absence of large-scale annotated medical VQA datasets presents a formidable obstacle to training a medical VQA model from scratch in an end-to-end manner. Existing works have been using image captioning dataset in the pre-training stage and fine-tuning to downstream VQA tasks. Following the same paradigm, we use a collection of public medical image captioning datasets to pre-train multimodality models in a self-supervised setup, and fine-tune to downstream medical VQA tasks. In the work, we propose a method that featured with Cross-Modal pre-training with Multiple Objectives (CMMO), which includes masked image modeling, masked language modeling, image-text matching, and image-text contrastive learning. The proposed method is designed to associate the visual features of medical images with corresponding medical concepts in captions, for learning aligned vision and language feature representations, and multi-modal interactions. The experimental results reveal that our proposed CMMO method outperforms state-of-the-art methods on three public medical VQA datasets, showing absolute improvements of 2.6%, 0.9%, and 4.0% on the VQA-RAD, PathVQA, and SLAKE dataset, respectively. We also conduct comprehensive ablation studies to validate our method, and visualize the attention maps which show a strong interpretability. The code and pre-trained weights will be released at https://github.com/pengfeiliHEU/CMMO.
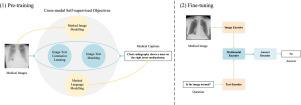
针对医学视觉问题解答的多目标跨模态自监督视觉语言预训练。
医学视觉问题解答(VQA)是一项旨在为医学图像问题提供答案的任务,它在推理过程中同时利用了视觉和文本信息。由于缺乏大规模的注释医学 VQA 数据集,要以端到端的方式从头开始训练医学 VQA 模型面临着巨大的障碍。现有的工作都是在预训练阶段使用图像标题数据集,然后根据下游的 VQA 任务进行微调。按照同样的模式,我们使用公共医疗图像标题数据集在自监督设置中预训练多模态模型,并根据下游医疗 VQA 任务进行微调。在这项工作中,我们提出了一种以多目标交叉模态预训练(CMMO)为特色的方法,其中包括屏蔽图像建模、屏蔽语言建模、图像-文本匹配和图像-文本对比学习。所提出的方法旨在将医学图像的视觉特征与标题中相应的医学概念联系起来,以学习一致的视觉和语言特征表征以及多模态交互。实验结果表明,我们提出的 CMMO 方法在三个公共医疗 VQA 数据集上的表现优于最先进的方法,在 VQA-RAD、PathVQA 和 SLAKE 数据集上的绝对改进率分别为 2.6%、0.9% 和 4.0%。我们还进行了全面的消融研究,以验证我们的方法,并对注意力图进行了可视化,结果显示了很强的可解释性。代码和预训练权重将在 https://github.com/pengfeiliHEU/CMMO 上发布。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Biomedical Informatics
医学-计算机:跨学科应用
CiteScore
8.90
自引率
6.70%
发文量
243
审稿时长
32 days
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


