{"title":"Bias in medical AI: Implications for clinical decision-making.","authors":"James L Cross, Michael A Choma, John A Onofrey","doi":"10.1371/journal.pdig.0000651","DOIUrl":null,"url":null,"abstract":"<p><p>Biases in medical artificial intelligence (AI) arise and compound throughout the AI lifecycle. These biases can have significant clinical consequences, especially in applications that involve clinical decision-making. Left unaddressed, biased medical AI can lead to substandard clinical decisions and the perpetuation and exacerbation of longstanding healthcare disparities. We discuss potential biases that can arise at different stages in the AI development pipeline and how they can affect AI algorithms and clinical decision-making. Bias can occur in data features and labels, model development and evaluation, deployment, and publication. Insufficient sample sizes for certain patient groups can result in suboptimal performance, algorithm underestimation, and clinically unmeaningful predictions. Missing patient findings can also produce biased model behavior, including capturable but nonrandomly missing data, such as diagnosis codes, and data that is not usually or not easily captured, such as social determinants of health. Expertly annotated labels used to train supervised learning models may reflect implicit cognitive biases or substandard care practices. Overreliance on performance metrics during model development may obscure bias and diminish a model's clinical utility. When applied to data outside the training cohort, model performance can deteriorate from previous validation and can do so differentially across subgroups. How end users interact with deployed solutions can introduce bias. Finally, where models are developed and published, and by whom, impacts the trajectories and priorities of future medical AI development. Solutions to mitigate bias must be implemented with care, which include the collection of large and diverse data sets, statistical debiasing methods, thorough model evaluation, emphasis on model interpretability, and standardized bias reporting and transparency requirements. Prior to real-world implementation in clinical settings, rigorous validation through clinical trials is critical to demonstrate unbiased application. Addressing biases across model development stages is crucial for ensuring all patients benefit equitably from the future of medical AI.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"3 11","pages":"e0000651"},"PeriodicalIF":7.7000,"publicationDate":"2024-11-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11542778/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000651","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
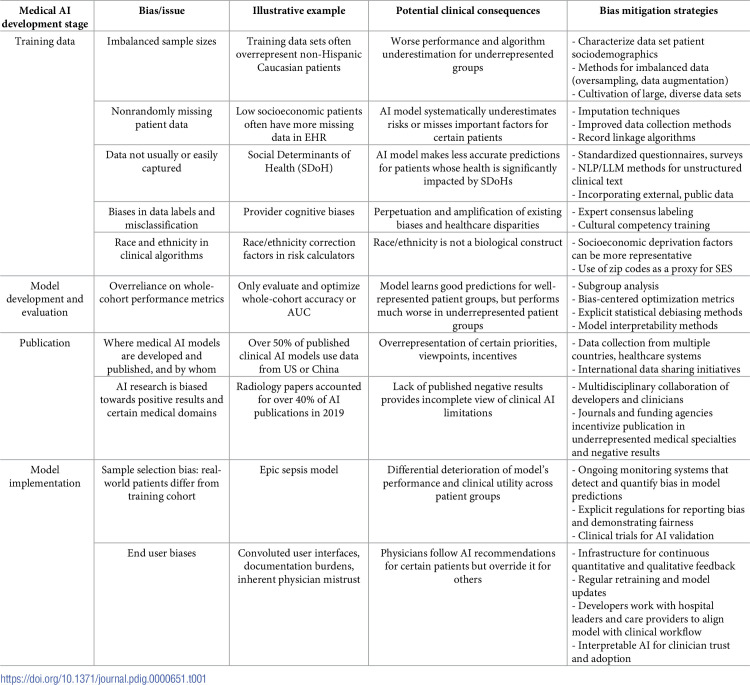
Biases in medical artificial intelligence (AI) arise and compound throughout the AI lifecycle. These biases can have significant clinical consequences, especially in applications that involve clinical decision-making. Left unaddressed, biased medical AI can lead to substandard clinical decisions and the perpetuation and exacerbation of longstanding healthcare disparities. We discuss potential biases that can arise at different stages in the AI development pipeline and how they can affect AI algorithms and clinical decision-making. Bias can occur in data features and labels, model development and evaluation, deployment, and publication. Insufficient sample sizes for certain patient groups can result in suboptimal performance, algorithm underestimation, and clinically unmeaningful predictions. Missing patient findings can also produce biased model behavior, including capturable but nonrandomly missing data, such as diagnosis codes, and data that is not usually or not easily captured, such as social determinants of health. Expertly annotated labels used to train supervised learning models may reflect implicit cognitive biases or substandard care practices. Overreliance on performance metrics during model development may obscure bias and diminish a model's clinical utility. When applied to data outside the training cohort, model performance can deteriorate from previous validation and can do so differentially across subgroups. How end users interact with deployed solutions can introduce bias. Finally, where models are developed and published, and by whom, impacts the trajectories and priorities of future medical AI development. Solutions to mitigate bias must be implemented with care, which include the collection of large and diverse data sets, statistical debiasing methods, thorough model evaluation, emphasis on model interpretability, and standardized bias reporting and transparency requirements. Prior to real-world implementation in clinical settings, rigorous validation through clinical trials is critical to demonstrate unbiased application. Addressing biases across model development stages is crucial for ensuring all patients benefit equitably from the future of medical AI.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


