A multi-label classification method based on transformer for deepfake detection
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
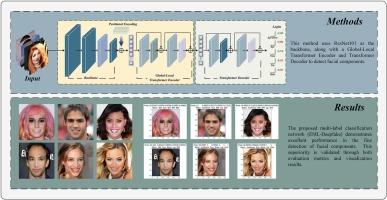
With the continuous development of hardware and deep learning technologies, existing forgery techniques are capable of more refined facial manipulations, making detection tasks increasingly challenging. Therefore, forgery detection cannot be viewed merely as a traditional binary classification task. To achieve finer forgery detection, we propose a method based on multi-label detection classification capable of identifying the presence of forgery in multiple facial components. Initially, the dataset undergoes preprocessing to meet the requirements of this task. Subsequently, we introduce a Detail-Enhancing Attention Module into the network to amplify subtle forgery traces in shallow feature maps and enhance the network's feature extraction capabilities. Additionally, we employ a Global–Local Transformer Decoder to improve the network's ability to focus on local information. Finally, extensive experiments demonstrate that our approach achieves 92.45% mAP and 90.23% mAUC, enabling precise detection of facial components in images, thus validating the effectiveness of our proposed method.
基于变压器的多标签分类方法用于深度伪造检测
随着硬件和深度学习技术的不断发展,现有的伪造技术能够对面部进行更精细的处理,使检测任务变得越来越具有挑战性。因此,赝品检测不能仅仅被视为传统的二元分类任务。为了实现更精细的伪造检测,我们提出了一种基于多标签检测分类的方法,能够识别多个面部组件中是否存在伪造。首先,对数据集进行预处理,以满足这项任务的要求。随后,我们在网络中引入了细节增强注意模块,以放大浅层特征图中细微的伪造痕迹,增强网络的特征提取能力。此外,我们还采用了全局-局部变换解码器,以提高网络关注局部信息的能力。最后,大量实验证明,我们的方法实现了 92.45% 的 mAP 和 90.23% 的 mAUC,能够精确检测图像中的面部成分,从而验证了我们所提方法的有效性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


