HIDIM: A novel framework of network intrusion detection for hierarchical dependency and class imbalance
IF 4.8
2区 计算机科学
Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
Abstract
Deep learning-based network intrusion detection has been extensively explored as a data-driven approach. Therefore, paying attention to the data’s characteristics is essential. By analyzing the attribute dependence and sample distribution of intrusion data, there are the following problems: “hierarchical dependency omission” and “decision boundary discontinuity.” The former means the previous attribute embedding models failed to incorporate network protocol hierarchy. The latter indicates that the small disjuncts distribution leads to sub-concept fragmentation, exacerbating the difficulty in handling class imbalance. To address these problems, we propose a novel detection framework for Hierarchical Dependency and Class Imbalance (HIDIM). First, we treat semantic attributes as words and introduce the protocol hierarchy of attributes into a paragraph embedding model. Second, we design a synthetic oversampling method. It adopts a mutual nearest neighbor approach to determine the boundaries of each disjunct. Then, it synthesizes high-quality samples within those boundary areas by crossing or mutating features based on their importance. The experimental results on multiple real-world datasets demonstrate that the proposed framework is superior to other state-of-the-art models in terms of accuracy, F1-score, and false negative rate by 2.23%, 2.12%, and 1.43% on average, respectively.
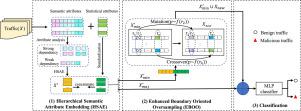
HIDIM:分层依赖和类不平衡的新型网络入侵检测框架
作为一种数据驱动的方法,基于深度学习的网络入侵检测已经得到了广泛的探索。因此,关注数据的特性至关重要。通过分析入侵数据的属性依赖性和样本分布,存在以下问题:"层次依赖遗漏 "和 "决策边界不连续"。前者意味着以往的属性嵌入模型未能将网络协议层次结构纳入其中。后者表明,小的不连续性分布导致子概念碎片化,加剧了处理类不平衡的难度。为了解决这些问题,我们提出了一个新颖的分层依赖和类不平衡(HIDIM)检测框架。首先,我们将语义属性视为词,并将属性的协议层次引入段落嵌入模型。其次,我们设计了一种合成超采样方法。它采用互为近邻的方法来确定每个分节的边界。然后,它根据特征的重要性,通过交叉或突变特征,在这些边界区域内合成高质量样本。在多个真实世界数据集上的实验结果表明,所提出的框架在准确率、F1 分数和假阴性率方面优于其他最先进的模型,平均分别提高了 2.23%、2.12% 和 1.43%。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computers & Security
工程技术-计算机:信息系统
CiteScore
12.40
自引率
7.10%
发文量
365
审稿时长
10.7 months
期刊介绍:
Computers & Security is the most respected technical journal in the IT security field. With its high-profile editorial board and informative regular features and columns, the journal is essential reading for IT security professionals around the world.
Computers & Security provides you with a unique blend of leading edge research and sound practical management advice. It is aimed at the professional involved with computer security, audit, control and data integrity in all sectors - industry, commerce and academia. Recognized worldwide as THE primary source of reference for applied research and technical expertise it is your first step to fully secure systems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


