Ensemble feature selection and tabular data augmentation with generative adversarial networks to enhance cutaneous melanoma identification and interpretability.
IF 6.1 3区 生物学Q1 MATHEMATICAL & COMPUTATIONAL BIOLOGY
Vanesa Gómez-Martínez, David Chushig-Muzo, Marit B Veierød, Conceição Granja, Cristina Soguero-Ruiz
{"title":"Ensemble feature selection and tabular data augmentation with generative adversarial networks to enhance cutaneous melanoma identification and interpretability.","authors":"Vanesa Gómez-Martínez, David Chushig-Muzo, Marit B Veierød, Conceição Granja, Cristina Soguero-Ruiz","doi":"10.1186/s13040-024-00397-7","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Cutaneous melanoma is the most aggressive form of skin cancer, responsible for most skin cancer-related deaths. Recent advances in artificial intelligence, jointly with the availability of public dermoscopy image datasets, have allowed to assist dermatologists in melanoma identification. While image feature extraction holds potential for melanoma detection, it often leads to high-dimensional data. Furthermore, most image datasets present the class imbalance problem, where a few classes have numerous samples, whereas others are under-represented.</p><p><strong>Methods: </strong>In this paper, we propose to combine ensemble feature selection (FS) methods and data augmentation with the conditional tabular generative adversarial networks (CTGAN) to enhance melanoma identification in imbalanced datasets. We employed dermoscopy images from two public datasets, PH2 and Derm7pt, which contain melanoma and not-melanoma lesions. To capture intrinsic information from skin lesions, we conduct two feature extraction (FE) approaches, including handcrafted and embedding features. For the former, color, geometric and first-, second-, and higher-order texture features were extracted, whereas for the latter, embeddings were obtained using ResNet-based models. To alleviate the high-dimensionality in the FE, ensemble FS with filter methods were used and evaluated. For data augmentation, we conducted a progressive analysis of the imbalance ratio (IR), related to the amount of synthetic samples created, and evaluated the impact on the predictive results. To gain interpretability on predictive models, we used SHAP, bootstrap resampling statistical tests and UMAP visualizations.</p><p><strong>Results: </strong>The combination of ensemble FS, CTGAN, and linear models achieved the best predictive results, achieving AUCROC values of 87% (with support vector machine and IR=0.9) and 76% (with LASSO and IR=1.0) for the PH2 and Derm7pt, respectively. We also identified that melanoma lesions were mainly characterized by features related to color, while not-melanoma lesions were characterized by texture features.</p><p><strong>Conclusions: </strong>Our results demonstrate the effectiveness of ensemble FS and synthetic data in the development of models that accurately identify melanoma. This research advances skin lesion analysis, contributing to both melanoma detection and the interpretation of main features for its identification.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"46"},"PeriodicalIF":6.1000,"publicationDate":"2024-10-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11526724/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00397-7","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Cutaneous melanoma is the most aggressive form of skin cancer, responsible for most skin cancer-related deaths. Recent advances in artificial intelligence, jointly with the availability of public dermoscopy image datasets, have allowed to assist dermatologists in melanoma identification. While image feature extraction holds potential for melanoma detection, it often leads to high-dimensional data. Furthermore, most image datasets present the class imbalance problem, where a few classes have numerous samples, whereas others are under-represented.
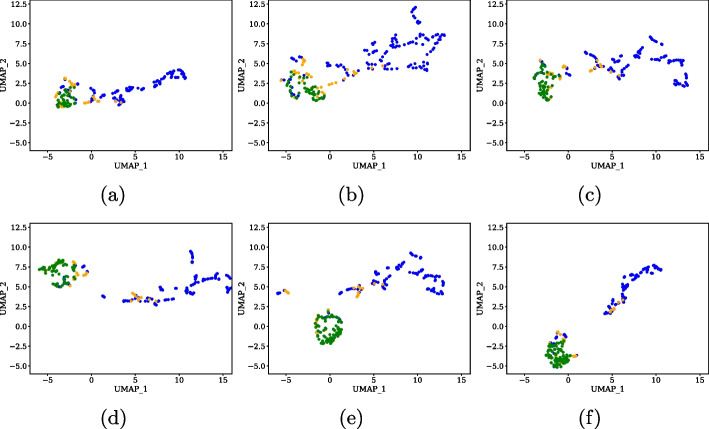
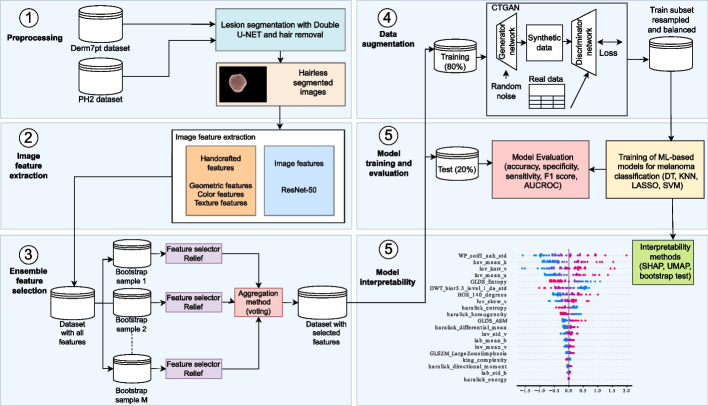
Methods: In this paper, we propose to combine ensemble feature selection (FS) methods and data augmentation with the conditional tabular generative adversarial networks (CTGAN) to enhance melanoma identification in imbalanced datasets. We employed dermoscopy images from two public datasets, PH2 and Derm7pt, which contain melanoma and not-melanoma lesions. To capture intrinsic information from skin lesions, we conduct two feature extraction (FE) approaches, including handcrafted and embedding features. For the former, color, geometric and first-, second-, and higher-order texture features were extracted, whereas for the latter, embeddings were obtained using ResNet-based models. To alleviate the high-dimensionality in the FE, ensemble FS with filter methods were used and evaluated. For data augmentation, we conducted a progressive analysis of the imbalance ratio (IR), related to the amount of synthetic samples created, and evaluated the impact on the predictive results. To gain interpretability on predictive models, we used SHAP, bootstrap resampling statistical tests and UMAP visualizations.
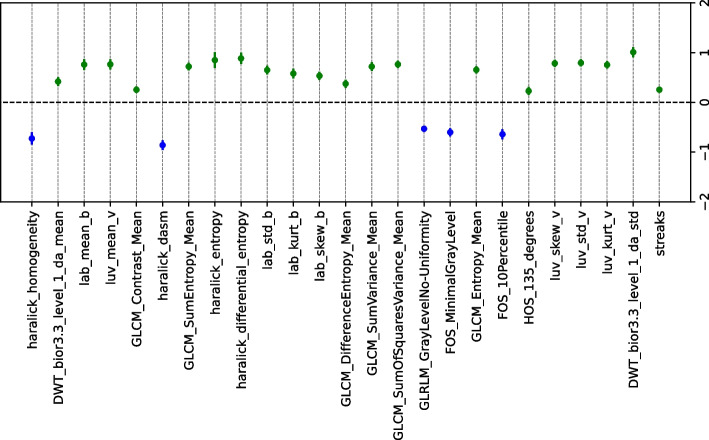
Results: The combination of ensemble FS, CTGAN, and linear models achieved the best predictive results, achieving AUCROC values of 87% (with support vector machine and IR=0.9) and 76% (with LASSO and IR=1.0) for the PH2 and Derm7pt, respectively. We also identified that melanoma lesions were mainly characterized by features related to color, while not-melanoma lesions were characterized by texture features.
Conclusions: Our results demonstrate the effectiveness of ensemble FS and synthetic data in the development of models that accurately identify melanoma. This research advances skin lesion analysis, contributing to both melanoma detection and the interpretation of main features for its identification.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


