Benchmarking data handling strategies for landslide susceptibility modeling using random forest workflows
IF 4.2
引用次数: 0
Abstract
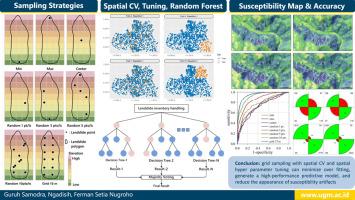
Machine learning (ML) algorithms are frequently used in landslide susceptibility modeling. Different data handling strategies may generate variations in landslide susceptibility modeling, even when using the same ML algorithm. This research aims to compare the combinations of inventory data handling, cross validation (CV), and hyperparameter tuning strategies to generate landslide susceptibility maps. The results are expected to provide a general strategy for landslide susceptibility modeling using ML techniques. The authors employed eight landslide inventory data handling scenarios to convert a landslide polygon into a landslide point, i.e., the landslide point is located on the toe (minimum height), on the scarp (maximum height), at the center of the landslide, randomly inside the polygon (1 point), randomly inside the polygon (3 points), randomly inside the polygon (5 points), randomly inside the polygon (10 points), and 15 m grid sampling. Random forest models using CV–nonspatial hyperparameter tuning, spatial CV–spatial hyperparameter tuning, and spatial CV–forward feature selection–no hyperparameter tuning were applied for each data handling strategy. The combination generated 24 random forest ML workflows, which are applied using a complete inventory of 743 landslides triggered by Tropical Cyclone Cempaka (2017) in Pacitan Regency, Indonesia, and 11 landslide controlling factors. The results show that grid sampling with spatial CV and spatial hyperparameter tuning is favorable because the strategy can minimize overfitting, generate a relatively high-performance predictive model, and reduce the appearance of susceptibility artifacts in the landslide area. Careful data inventory handling, CV, and hyperparameter tuning strategies should be considered in landslide susceptibility modeling to increase the applicability of landslide susceptibility maps in practical application.
利用随机森林工作流程为滑坡易发性建模的数据处理策略制定基准
机器学习(ML)算法经常用于滑坡易感性建模。即使使用相同的 ML 算法,不同的数据处理策略也可能导致滑坡易感性建模的差异。本研究旨在比较库存数据处理、交叉验证(CV)和超参数调整策略的组合,以生成滑坡易感性图。研究结果有望为使用 ML 技术进行滑坡易感性建模提供通用策略。作者采用了八种滑坡清单数据处理方案,将滑坡多边形转换为滑坡点,即滑坡点位于坡脚(最小高度)、坡面(最大高度)、滑坡中心、多边形内随机(1 点)、多边形内随机(3 点)、多边形内随机(5 点)、多边形内随机(10 点)和 15 米网格采样。每种数据处理策略都采用了 CV-非空间超参数调整、空间 CV-空间超参数调整和空间 CV-前向特征选择-无超参数调整的随机森林模型。组合生成了 24 个随机森林 ML 工作流,并将其应用于印尼帕契坦地区热带气旋 "肯帕卡"(2017 年)引发的 743 次滑坡的完整清单和 11 个滑坡控制因素。结果表明,网格采样加上空间 CV 和空间超参数调整是有利的,因为该策略可以最大限度地减少过拟合,生成性能相对较高的预测模型,并减少滑坡区域易感性假象的出现。在滑坡易感性建模中应考虑谨慎的数据清单处理、CV 和超参数调整策略,以提高滑坡易感性图在实际应用中的适用性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


