{"title":"Image Segmentation Evaluation With the Dice Index: Methodological Issues","authors":"Mohamed L. Seghier","doi":"10.1002/ima.23203","DOIUrl":null,"url":null,"abstract":"<p>In this editorial, I call for more clarity and transparency when calculating and reporting the Dice index to evaluate the performance of biomedical image segmentation methods. Despite many existing guidelines for best practices for assessing and reporting the performance of automated methods [<span>1, 2</span>], there is still a lack of clarity on why and how performance metrics were selected and assessed. I have seen articles where, for instance, Dice indices (i) were erroneously reported as smaller than intersection-over-union values, (ii) oddly increased from moderate to excellent values after including images with no actual positive instances, (iii) were drastically affected by image cropping or zero-padding, (iv) did not make sense in the light of the reported precision and sensitivity values, (v) showed opposite trends to F1 scores, (vi) were wrongly interpreted as accuracy measures, (vii) used as a measure of detection success rather than segmentation success, (viii) were used to rank methods that varied considerably in terms of the number of false positives and false negatives, (ix) were averaged across segmented structures of interest with highly variable sizes, and (x) were directly compared to other Dice indices from previous studies despite being tested on completely different datasets. It is important to remind our authors what one can (or cannot) do with the Dice index for biomedical image segmentation.</p><p>As the Dice index is one of the preferred metrics to assess segmentation performance and is widely used in many challenges and benchmarks to rank models [<span>3</span>], it is paramount that authors calculate it correctly and report it clearly and transparently. Below, I discuss conceptual and methodological issues about the Dice index before providing a list of 10 simple rules for optimal and transparent reporting of the Dice index. By improving transparency and clarity, I believe readers will draw the right conclusions about methods evaluation, which will ultimately help improve interpretability and replicability in biomedical data processing.</p><p>The discussion below applies to any image segmentation problem, imaging modality, 2D (slices) or 3D (volumes) inputs, and segmentation tasks (e.g., segmenting abnormalities or typical structures and organs). Examples will be taken from the automated segmentation of stroke lesions in brain scans.</p><p>Put another way, the Dice index codes how the positives declared by an automated method match the actual positives of the ground truth. We have <span></span><math>\n <semantics>\n <mrow>\n <mtext>Dice</mtext>\n <mfenced>\n <mrow>\n <mi>A</mi>\n <mo>,</mo>\n <mi>A</mi>\n </mrow>\n </mfenced>\n <mo>=</mo>\n <mn>1</mn>\n <mo>;</mo>\n <mtext>Dice</mtext>\n <mfenced>\n <mrow>\n <mi>A</mi>\n <mo>,</mo>\n <mn>1</mn>\n <mo>−</mo>\n <mi>A</mi>\n </mrow>\n </mfenced>\n <mo>=</mo>\n <mn>0</mn>\n <mo>;</mo>\n <mtext>Dice</mtext>\n <mfenced>\n <mrow>\n <mi>A</mi>\n <mo>,</mo>\n <mi>B</mi>\n </mrow>\n </mfenced>\n <mo>=</mo>\n <mtext>Dice</mtext>\n <mfenced>\n <mrow>\n <mi>B</mi>\n <mo>,</mo>\n <mi>A</mi>\n </mrow>\n </mfenced>\n </mrow>\n <annotation>$$ \\mathrm{Dice}\\left(A,A\\right)=1;\\mathrm{Dice}\\left(A,1-A\\right)=0;\\mathrm{Dice}\\left(A,B\\right)=\\mathrm{Dice}\\left(B,A\\right) $$</annotation>\n </semantics></math>. It is worth mentioning that the same Dice value can represent multiple different configurations between two images, <i>A</i> and <i>B</i>.</p><p>The Dice index has many well-known limitations (see Figure 1 for an illustration), which explains why additional performance metrics are usually needed [<span>8</span>] for completeness.</p><p>It is a well-documented fact that Dice is agnostic to true negatives. This means that for the same overlap to the union ratio, the Dice index will be the same regardless of the total size of the image (e.g., zoom-in/out, cropping, resampling, or zero-padding do not affect the Dice index). This ‘insensitivity’ to true negatives is, in fact, one of its advantages for segmentation because, in medical images, the structure of interest (a stroke lesion) is typically small, which means that data are highly imbalanced when it comes to the definition of positives and negatives. For tiny lesions, for example, an accuracy metric that accounts for true negatives will always return excellent accuracy values regardless of the method's success in delineating such small lesions. A very high Dice value (> 0.9) implies excellent accuracy, but excellent accuracy does not necessarily imply very high Dice values. This is why we have this conditional statement: an excellent Dice is <i>sufficient</i> for excellent accuracy. Note that when true negatives tend to zero, the accuracy becomes similar to the intersection over union (IOU).</p><p>Dice is a monotonic function of the Jaccard index (or IOU). Both metrics quantify similar information, and if one metric is provided, then there is no need to provide the other metric when assessing the performance of a given automated method [<span>8</span>]. Dice is widely used because it shows higher values than IOU for the same degree of overlap (TP) between the two images, thereby putting more importance on TP. However, IOU might offer a more intuitive evaluation of the segmentation performance because it directly measures the proportion of overlapping pixels/voxels relative to the total number of unique pixels/voxels in both images.</p><p>Overall, if both indices are provided, it is important to ensure coherent results (e.g., if Dice values were smaller than IOU values, then something went wrong with their calculation).</p><p>This is an important limitation of the Dice index. Because the Dice index is equivalent to the harmonic mean of precision and recall, it cannot distinguish between methods with different FP-to-FN ratios. In other words, the Dice index treats all segmentation errors equally, regardless of their location or significance. For instance, two methods can show the same total number of false instances (FP + FN), but one method might have poor sensitivity (large FN), and the other might have poor specificity (large FP). This is why it is very useful to report precision and sensitivity/recall in addition to Dice indices. This has implications for evaluating the usefulness of a given method depending on the application of interest. For instance, a method with high specificity might be preferred over one with high sensitivity or vice versa for some specific clinical applications. For example, a presurgical segmentation of a high-grade tumour might prefer a high sensitivity method to ensure all malignant tumoural tissue has been demarcated for subsequent resection. In contrast, a presurgical segmentation of a benign tumour might prefer a high specificity method to minimise postsurgical morbidity.</p><p>This limitation comes from the fact that Dice does not explicitly account for spatial features (object's shape or location). This limitation concerns the scenario of two methods having the same Dice but being affected by different features or locations of the structure of interest. For instance, if one method consistently segments the medial parts of a stroke lesion while another method performs better at lateral parts, Dice might not reflect well such biases if both methods produce similar overlaps with the ground truth. For example, this scenario can be seen in segmenting large stroke lesions that extend medially to the ventricles. Some methods might show bias in oversegmenting medial parts of the lesion near the ventricles compared to other methods (i.e., the presence of FP in medial or lateral parts has the same impact on the Dice index).</p><p>Some studies have discussed this limitation, but it is not always acknowledged, particularly for segmenting lesions or structures with a high size variability. Specifically, stroke lesions can vary from a few voxels (0.1 cm<sup>3</sup>) to thousands of voxels (> 300 cm<sup>3</sup>) in size. For such a wide range of lesion sizes, a small FP or FN will have a different impact on the Dice index. For example, for an excellent segmentation method that produces only one FP or FN, the Dice index will be very high for large lesions but moderate or poor for small ones. This can translate into an overestimation of segmentation performance in images with large lesions where other small but clinically significant lesions are missed. This is why providing the distribution (histogram) of the lesion size of both training and test samples is recommended. It is also useful to calculate the average Dice separately for small, medium and large lesions or provide a scatter plot of Dice values against lesion size; for a similar rationale (see [<span>9, 10</span>]). This would help the authors make the right recommendations about which type of lesions their method works better for (e.g., a given method might be very good for large but poor for tiny lesions).</p><p>This issue is not often discussed, particularly when segmenting small lesions. For example, a small lesion might be extremely hard to segment fully, but its detection might still be clinically useful. If a small lesion has a size of two voxels, then an automated method showing one voxel overlap with no FP will have a moderate Dice index of 0.66 even though the method successfully detected such a tiny lesion. This is why it is important to explain whether clinical relevance concerns the demarcation of the lesions or their detection in the images. This is because the latter might not always be assessed with the Dice index in a meaningful way.</p><p>In this context, if the application of interest is about segmentation and demarcation of the full lesion extent, then a classic Dice can still be used. However, if detecting multiple focal lesions is the main question of interest (e.g., detection of cerebral microbleeds or small MS lesions), then Dice can be calculated not in a voxel-wise but in a lesion-wise manner (e.g., TP will index the number of detected lesions regardless of whether they were fully delineated or not).</p><p>This is a common problem for the classic Dice index, that is, all ground-truth voxels are treated similarly regardless of how much uncertainty is associated with each voxel. This issue reflects, for instance, the case of a ground truth defined differently across experts or operators, which means that each voxel of the ground truth is not labelled with the same confidence. For example, in light of existing interoperator variability in manual lesion segmentation [<span>11, 12</span>], two or three experts might delineate lesions differently, and thus, some ground-truth pixels/voxels are common across experts while others are different. Should a false positive have the same meaning for the latter compared to the former? Unfortunately, this is not accounted for in the classic Dice index.</p><p>One way, in the case of a continuous ground truth that codes uncertainty, is to use other versions of the Dice index for continuous quantities [<span>13</span>]. Alternatively, if more than one binary ground-truth definition exists, one can generate an overlap map across the existing definitions. The overlap map can thus index the agreement between experts as a percentage of experts who declared a given voxel as a true lesion. Voxels with values equal to one would represent voxels with high confidence to be a lesion, and thus, those voxels must have more weight in the definition of TP and FN. Likewise, voxels with small values in the overlap map might be assigned a small penalty in the definition of FP. Overall, there is no consensus in the current literature on incorporating interoperator variability in the optimal calculation of performance metrics, including the possibility of defining a weighted version of the Dice index.[<span>14</span>] This issue warrants further investigation.</p><p>I believe this problem is somehow overlooked in the current literature about image segmentation. This concerns images with zero ground truth or no actual positive instances. This scenario differs from cases with unknown ground truth because zero positives mean a known ground truth about true negatives. Put another way, zero positive instances reflect the expert decision that the structure of interest does not exist (e.g., a scan with no lesion), which should translate into zero true positives and zero false negatives for an ideal automated method. A typical example is, for instance, the segmentation of lesions in normal scans that do not display any visible abnormalities. Here, I would like to explain why this special case must be considered in segmentation tasks in a robust and transparent manner. I note that how Dice is reported for such cases in the current literature lacks clarity and transparency.</p><p>In this case, Dice = 1 when FP = 0 (i.e., the automated method correctly predicted the absence of lesions); otherwise, Dice < <i>ε</i> when FP > 0. Accordingly, the Dice index is equivalent to the percentage of ‘normal’ images for which the automated method returned no positives.</p><p>However, this ‘trick’ to make the Dice index calculable for cases with zero positives suffers three main limitations. First, this smooth version returns a near-zero Dice value regardless of whether the automated segmentation produced only one or thousands of false positives. Second, this method would generate a crisp distribution of Dice indices for cases with no positive instances (Dice values concentrated at either one or near zero). Such crisp distribution is then averaged (mixed) with a more continuous Dice distribution for images with known positive instances, which makes the final Dice averages difficult to interpret. Third, this method might lead to inflated performance, particularly for methods with high specificity tested on datasets with a large number of images with no positive instances. To illustrate this point, we look at the scenario of segmenting focal lesions where those lesions are only present in a few slices of 3D scans. Let us assume we are testing an automated segmentation method with poor sensitivity but excellent specificity. When the method was tested on 100 slices with visible lesions and known ground truth, Dice was equal to 0.5. However, this moderate Dice index increased to 0.8 when an extra 150 slices with no lesions were included. Such inflated Dice values do not tell the whole story.</p><p>Different strategies have been devised to address this problem. I discuss below why those strategies are not always optimal. First, previous work suggested segmenting only slices or volumes with visible stroke lesions. For models that operate on 2D slices, this can be done by cropping the 3D scans in the inferior–superior direction when using axial slices, in the left–right direction when using sagittal slices, or in the anterior–posterior direction when using coronal slices. For models that operate on 3D volumes, volumes with no lesions are simply excluded. While this approach allows Dice indices to be calculated on images with visible lesions, it does not test the method's robustness on ‘normal’ images without lesions. If an expert has to predefine relevant slices/volumes with lesions, then segmentation will cease being fully automated (it can be qualified as semiautomated). On the other hand, if relevant slices are selected by another AI tool that classifies images as lesioned or normal, then any classification errors will propagate to later segmentation stages. Second, another strategy is to consider the true negatives in the normal slices as true ‘positives’ (e.g., true positives will equal the whole slice). In that case, the Dice index will measure the similarity between the whole image and the complement of the segmented image (i.e., one minus the identified binary lesions by the automated method). Although this method can yield calculable Dice indices, it might lead to inflated Dice values, particularly for methods with poor sensitivity.</p><p>Given that this problem has no easy fix, I suggest reporting the Dice index separately for images with and without lesions. For example, let us assume a segmentation problem with 700 images with lesions and 800 images without lesions. On the 700 images, Dice was found to be 0.65. For the 800 images, the model returned no lesions (no FP) on 680 images. In that scenario, Dice can be reported as a two-value vector: Dice = (0.65, 0.85). The authors can report Dice values in two columns: one column for images with lesions, and a second column for normal images without lesions. I believe this might be more informative than a single average value. For example, assuming the same number of images with or without lesions, two models can give the same average Dice (e.g., Dice = 0.7), yet they might reflect different performances: Model 1 with Dice = (0.5, 0.9) and Model 2 with Dice = (0.9, 0.5). One can deduce that Model 1 has good specificity in the absence of lesions but average performance for delineating existing lesions, whereas Model 2 has excellent lesion segmentation but tends to produce too many false positives for images without lesions. This insight can help the reader understand the model's performance in a more comprehensive way.</p><p>The author declare no conflict of interest.</p>","PeriodicalId":14027,"journal":{"name":"International Journal of Imaging Systems and Technology","volume":"34 6","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-10-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ima.23203","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Imaging Systems and Technology","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ima.23203","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
Abstract
In this editorial, I call for more clarity and transparency when calculating and reporting the Dice index to evaluate the performance of biomedical image segmentation methods. Despite many existing guidelines for best practices for assessing and reporting the performance of automated methods [1, 2], there is still a lack of clarity on why and how performance metrics were selected and assessed. I have seen articles where, for instance, Dice indices (i) were erroneously reported as smaller than intersection-over-union values, (ii) oddly increased from moderate to excellent values after including images with no actual positive instances, (iii) were drastically affected by image cropping or zero-padding, (iv) did not make sense in the light of the reported precision and sensitivity values, (v) showed opposite trends to F1 scores, (vi) were wrongly interpreted as accuracy measures, (vii) used as a measure of detection success rather than segmentation success, (viii) were used to rank methods that varied considerably in terms of the number of false positives and false negatives, (ix) were averaged across segmented structures of interest with highly variable sizes, and (x) were directly compared to other Dice indices from previous studies despite being tested on completely different datasets. It is important to remind our authors what one can (or cannot) do with the Dice index for biomedical image segmentation.
As the Dice index is one of the preferred metrics to assess segmentation performance and is widely used in many challenges and benchmarks to rank models [3], it is paramount that authors calculate it correctly and report it clearly and transparently. Below, I discuss conceptual and methodological issues about the Dice index before providing a list of 10 simple rules for optimal and transparent reporting of the Dice index. By improving transparency and clarity, I believe readers will draw the right conclusions about methods evaluation, which will ultimately help improve interpretability and replicability in biomedical data processing.
The discussion below applies to any image segmentation problem, imaging modality, 2D (slices) or 3D (volumes) inputs, and segmentation tasks (e.g., segmenting abnormalities or typical structures and organs). Examples will be taken from the automated segmentation of stroke lesions in brain scans.
Put another way, the Dice index codes how the positives declared by an automated method match the actual positives of the ground truth. We have . It is worth mentioning that the same Dice value can represent multiple different configurations between two images, A and B.
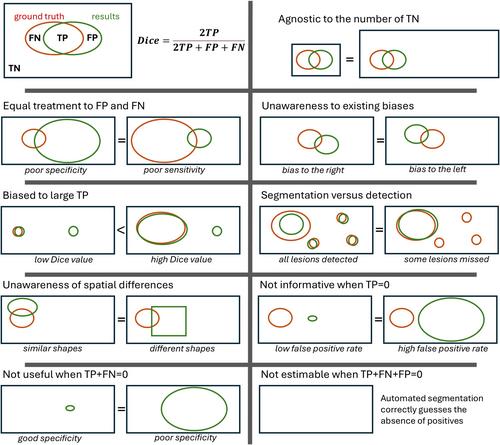
The Dice index has many well-known limitations (see Figure 1 for an illustration), which explains why additional performance metrics are usually needed [8] for completeness.
It is a well-documented fact that Dice is agnostic to true negatives. This means that for the same overlap to the union ratio, the Dice index will be the same regardless of the total size of the image (e.g., zoom-in/out, cropping, resampling, or zero-padding do not affect the Dice index). This ‘insensitivity’ to true negatives is, in fact, one of its advantages for segmentation because, in medical images, the structure of interest (a stroke lesion) is typically small, which means that data are highly imbalanced when it comes to the definition of positives and negatives. For tiny lesions, for example, an accuracy metric that accounts for true negatives will always return excellent accuracy values regardless of the method's success in delineating such small lesions. A very high Dice value (> 0.9) implies excellent accuracy, but excellent accuracy does not necessarily imply very high Dice values. This is why we have this conditional statement: an excellent Dice is sufficient for excellent accuracy. Note that when true negatives tend to zero, the accuracy becomes similar to the intersection over union (IOU).
Dice is a monotonic function of the Jaccard index (or IOU). Both metrics quantify similar information, and if one metric is provided, then there is no need to provide the other metric when assessing the performance of a given automated method [8]. Dice is widely used because it shows higher values than IOU for the same degree of overlap (TP) between the two images, thereby putting more importance on TP. However, IOU might offer a more intuitive evaluation of the segmentation performance because it directly measures the proportion of overlapping pixels/voxels relative to the total number of unique pixels/voxels in both images.
Overall, if both indices are provided, it is important to ensure coherent results (e.g., if Dice values were smaller than IOU values, then something went wrong with their calculation).
This is an important limitation of the Dice index. Because the Dice index is equivalent to the harmonic mean of precision and recall, it cannot distinguish between methods with different FP-to-FN ratios. In other words, the Dice index treats all segmentation errors equally, regardless of their location or significance. For instance, two methods can show the same total number of false instances (FP + FN), but one method might have poor sensitivity (large FN), and the other might have poor specificity (large FP). This is why it is very useful to report precision and sensitivity/recall in addition to Dice indices. This has implications for evaluating the usefulness of a given method depending on the application of interest. For instance, a method with high specificity might be preferred over one with high sensitivity or vice versa for some specific clinical applications. For example, a presurgical segmentation of a high-grade tumour might prefer a high sensitivity method to ensure all malignant tumoural tissue has been demarcated for subsequent resection. In contrast, a presurgical segmentation of a benign tumour might prefer a high specificity method to minimise postsurgical morbidity.
This limitation comes from the fact that Dice does not explicitly account for spatial features (object's shape or location). This limitation concerns the scenario of two methods having the same Dice but being affected by different features or locations of the structure of interest. For instance, if one method consistently segments the medial parts of a stroke lesion while another method performs better at lateral parts, Dice might not reflect well such biases if both methods produce similar overlaps with the ground truth. For example, this scenario can be seen in segmenting large stroke lesions that extend medially to the ventricles. Some methods might show bias in oversegmenting medial parts of the lesion near the ventricles compared to other methods (i.e., the presence of FP in medial or lateral parts has the same impact on the Dice index).
Some studies have discussed this limitation, but it is not always acknowledged, particularly for segmenting lesions or structures with a high size variability. Specifically, stroke lesions can vary from a few voxels (0.1 cm3) to thousands of voxels (> 300 cm3) in size. For such a wide range of lesion sizes, a small FP or FN will have a different impact on the Dice index. For example, for an excellent segmentation method that produces only one FP or FN, the Dice index will be very high for large lesions but moderate or poor for small ones. This can translate into an overestimation of segmentation performance in images with large lesions where other small but clinically significant lesions are missed. This is why providing the distribution (histogram) of the lesion size of both training and test samples is recommended. It is also useful to calculate the average Dice separately for small, medium and large lesions or provide a scatter plot of Dice values against lesion size; for a similar rationale (see [9, 10]). This would help the authors make the right recommendations about which type of lesions their method works better for (e.g., a given method might be very good for large but poor for tiny lesions).
This issue is not often discussed, particularly when segmenting small lesions. For example, a small lesion might be extremely hard to segment fully, but its detection might still be clinically useful. If a small lesion has a size of two voxels, then an automated method showing one voxel overlap with no FP will have a moderate Dice index of 0.66 even though the method successfully detected such a tiny lesion. This is why it is important to explain whether clinical relevance concerns the demarcation of the lesions or their detection in the images. This is because the latter might not always be assessed with the Dice index in a meaningful way.
In this context, if the application of interest is about segmentation and demarcation of the full lesion extent, then a classic Dice can still be used. However, if detecting multiple focal lesions is the main question of interest (e.g., detection of cerebral microbleeds or small MS lesions), then Dice can be calculated not in a voxel-wise but in a lesion-wise manner (e.g., TP will index the number of detected lesions regardless of whether they were fully delineated or not).
This is a common problem for the classic Dice index, that is, all ground-truth voxels are treated similarly regardless of how much uncertainty is associated with each voxel. This issue reflects, for instance, the case of a ground truth defined differently across experts or operators, which means that each voxel of the ground truth is not labelled with the same confidence. For example, in light of existing interoperator variability in manual lesion segmentation [11, 12], two or three experts might delineate lesions differently, and thus, some ground-truth pixels/voxels are common across experts while others are different. Should a false positive have the same meaning for the latter compared to the former? Unfortunately, this is not accounted for in the classic Dice index.
One way, in the case of a continuous ground truth that codes uncertainty, is to use other versions of the Dice index for continuous quantities [13]. Alternatively, if more than one binary ground-truth definition exists, one can generate an overlap map across the existing definitions. The overlap map can thus index the agreement between experts as a percentage of experts who declared a given voxel as a true lesion. Voxels with values equal to one would represent voxels with high confidence to be a lesion, and thus, those voxels must have more weight in the definition of TP and FN. Likewise, voxels with small values in the overlap map might be assigned a small penalty in the definition of FP. Overall, there is no consensus in the current literature on incorporating interoperator variability in the optimal calculation of performance metrics, including the possibility of defining a weighted version of the Dice index.[14] This issue warrants further investigation.
I believe this problem is somehow overlooked in the current literature about image segmentation. This concerns images with zero ground truth or no actual positive instances. This scenario differs from cases with unknown ground truth because zero positives mean a known ground truth about true negatives. Put another way, zero positive instances reflect the expert decision that the structure of interest does not exist (e.g., a scan with no lesion), which should translate into zero true positives and zero false negatives for an ideal automated method. A typical example is, for instance, the segmentation of lesions in normal scans that do not display any visible abnormalities. Here, I would like to explain why this special case must be considered in segmentation tasks in a robust and transparent manner. I note that how Dice is reported for such cases in the current literature lacks clarity and transparency.
In this case, Dice = 1 when FP = 0 (i.e., the automated method correctly predicted the absence of lesions); otherwise, Dice < ε when FP > 0. Accordingly, the Dice index is equivalent to the percentage of ‘normal’ images for which the automated method returned no positives.
However, this ‘trick’ to make the Dice index calculable for cases with zero positives suffers three main limitations. First, this smooth version returns a near-zero Dice value regardless of whether the automated segmentation produced only one or thousands of false positives. Second, this method would generate a crisp distribution of Dice indices for cases with no positive instances (Dice values concentrated at either one or near zero). Such crisp distribution is then averaged (mixed) with a more continuous Dice distribution for images with known positive instances, which makes the final Dice averages difficult to interpret. Third, this method might lead to inflated performance, particularly for methods with high specificity tested on datasets with a large number of images with no positive instances. To illustrate this point, we look at the scenario of segmenting focal lesions where those lesions are only present in a few slices of 3D scans. Let us assume we are testing an automated segmentation method with poor sensitivity but excellent specificity. When the method was tested on 100 slices with visible lesions and known ground truth, Dice was equal to 0.5. However, this moderate Dice index increased to 0.8 when an extra 150 slices with no lesions were included. Such inflated Dice values do not tell the whole story.
Different strategies have been devised to address this problem. I discuss below why those strategies are not always optimal. First, previous work suggested segmenting only slices or volumes with visible stroke lesions. For models that operate on 2D slices, this can be done by cropping the 3D scans in the inferior–superior direction when using axial slices, in the left–right direction when using sagittal slices, or in the anterior–posterior direction when using coronal slices. For models that operate on 3D volumes, volumes with no lesions are simply excluded. While this approach allows Dice indices to be calculated on images with visible lesions, it does not test the method's robustness on ‘normal’ images without lesions. If an expert has to predefine relevant slices/volumes with lesions, then segmentation will cease being fully automated (it can be qualified as semiautomated). On the other hand, if relevant slices are selected by another AI tool that classifies images as lesioned or normal, then any classification errors will propagate to later segmentation stages. Second, another strategy is to consider the true negatives in the normal slices as true ‘positives’ (e.g., true positives will equal the whole slice). In that case, the Dice index will measure the similarity between the whole image and the complement of the segmented image (i.e., one minus the identified binary lesions by the automated method). Although this method can yield calculable Dice indices, it might lead to inflated Dice values, particularly for methods with poor sensitivity.
Given that this problem has no easy fix, I suggest reporting the Dice index separately for images with and without lesions. For example, let us assume a segmentation problem with 700 images with lesions and 800 images without lesions. On the 700 images, Dice was found to be 0.65. For the 800 images, the model returned no lesions (no FP) on 680 images. In that scenario, Dice can be reported as a two-value vector: Dice = (0.65, 0.85). The authors can report Dice values in two columns: one column for images with lesions, and a second column for normal images without lesions. I believe this might be more informative than a single average value. For example, assuming the same number of images with or without lesions, two models can give the same average Dice (e.g., Dice = 0.7), yet they might reflect different performances: Model 1 with Dice = (0.5, 0.9) and Model 2 with Dice = (0.9, 0.5). One can deduce that Model 1 has good specificity in the absence of lesions but average performance for delineating existing lesions, whereas Model 2 has excellent lesion segmentation but tends to produce too many false positives for images without lesions. This insight can help the reader understand the model's performance in a more comprehensive way.
期刊介绍:
The International Journal of Imaging Systems and Technology (IMA) is a forum for the exchange of ideas and results relevant to imaging systems, including imaging physics and informatics. The journal covers all imaging modalities in humans and animals.
IMA accepts technically sound and scientifically rigorous research in the interdisciplinary field of imaging, including relevant algorithmic research and hardware and software development, and their applications relevant to medical research. The journal provides a platform to publish original research in structural and functional imaging.
The journal is also open to imaging studies of the human body and on animals that describe novel diagnostic imaging and analyses methods. Technical, theoretical, and clinical research in both normal and clinical populations is encouraged. Submissions describing methods, software, databases, replication studies as well as negative results are also considered.
The scope of the journal includes, but is not limited to, the following in the context of biomedical research:
Imaging and neuro-imaging modalities: structural MRI, functional MRI, PET, SPECT, CT, ultrasound, EEG, MEG, NIRS etc.;
Neuromodulation and brain stimulation techniques such as TMS and tDCS;
Software and hardware for imaging, especially related to human and animal health;
Image segmentation in normal and clinical populations;
Pattern analysis and classification using machine learning techniques;
Computational modeling and analysis;
Brain connectivity and connectomics;
Systems-level characterization of brain function;
Neural networks and neurorobotics;
Computer vision, based on human/animal physiology;
Brain-computer interface (BCI) technology;
Big data, databasing and data mining.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


