A proteome-wide association study identifies putative causal proteins for breast cancer risk
IF 6.4
1区 医学
Q1 ONCOLOGY
引用次数: 0
Abstract
Genome-wide association studies (GWAS) have identified more than 200 breast cancer risk-associated genetic loci, yet the causal genes and biological mechanisms for most loci remain elusive. Proteins, as final gene products, are pivotal in cellular function. In this study, we conducted a proteome-wide association study (PWAS) to identify proteins in breast tissue related to breast cancer risk. We profiled the proteome in fresh frozen breast tissue samples from 120 cancer-free European-ancestry women from the Susan G. Komen Tissue Bank (KTB). Protein expression levels were log2-transformed then normalized via quantile and inverse-rank transformations. GWAS data were also generated for these 120 samples. These data were used to build statistical models to predict protein expression levels via cis-genetic variants using the elastic net method. The prediction models were then applied to the GWAS summary statistics data of 133,384 breast cancer cases and 113,789 controls to assess the associations of genetically predicted protein expression levels with breast cancer risk overall and its subtypes using the S-PrediXcan method. A total of 6388 proteins were detected in the normal breast tissue samples from 120 women with a high detection false discovery rate (FDR) p value < 0.01. Among the 5820 proteins detected in more than 80% of participants, prediction models were successfully built for 2060 proteins with R > 0.1 and P < 0.05. Among these 2060 proteins, five proteins were significantly associated with overall breast cancer risk at an FDR p value < 0.1. Among these five proteins, the corresponding genes for proteins COPG1, DCTN3, and DDX6 were located at least 1 Megabase away from the GWAS-identified breast cancer risk variants. COPG1 was associated with an increased risk of breast cancer with a p value of 8.54 × 10–4. Both DCTN3 and DDX6 were associated with a decreased risk of breast cancer with p values of 1.01 × 10–3 and 3.25 × 10–4, respectively. The corresponding genes for the remaining two proteins, LSP1 and DNAJA3, were located in previously GWAS-identified breast cancer risk loci. After adjusting for GWAS-identified risk variants, the association for DNAJA3 was still significant (p value of 9.15 × 10–5 and adjusted p value of 1.94 × 10–4). However, the significance for LSP1 became weaker with a p value of 0.62. Stratification analyses by breast cancer subtypes identified three proteins, SMARCC1, LSP1, and NCKAP1L, associated with luminal A, luminal B, and ER-positive breast cancer. NCKAP1L was located at least 1Mb away from the GWAS-identified breast cancer risk variants. After adjusting for GWAS-identified breast cancer risk variants, the association for protein LSP1 was still significant (adjusted p value of 6.43 × 10–3 for luminal B subtype). We conducted the first breast-tissue-based PWAS and identified seven proteins associated with breast cancer, including five proteins not previously implicated. These findings help improve our understanding of the underlying genetic mechanism of breast cancer development.
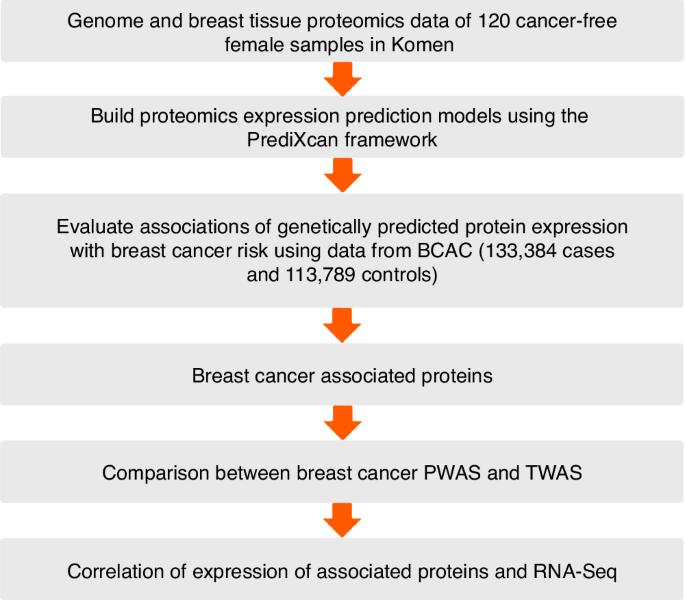
一项全蛋白质组关联研究确定了乳腺癌风险的潜在致病蛋白质。
背景:全基因组关联研究(GWAS)已经发现了 200 多个与乳腺癌风险相关的基因位点,但大多数位点的致病基因和生物学机制仍然难以确定。蛋白质作为基因的最终产物,在细胞功能中起着举足轻重的作用。在这项研究中,我们进行了一项全蛋白质组关联研究(PWAS),以确定乳腺组织中与乳腺癌风险相关的蛋白质:我们分析了苏珊-科曼组织库(KTB)中 120 名无癌症欧洲裔女性的新鲜冷冻乳腺组织样本中的蛋白质组。蛋白质表达水平经过对数2转换,然后通过量纲和反秩转换进行归一化处理。这 120 个样本还生成了 GWAS 数据。这些数据被用来建立统计模型,使用弹性网方法通过顺式遗传变异预测蛋白质表达水平。然后将预测模型应用于 133,384 例乳腺癌病例和 113,789 例对照的 GWAS 统计摘要数据,使用 S-PrediXcan 方法评估基因预测的蛋白质表达水平与乳腺癌总体风险及其亚型的关联:结果:在 120 名女性的正常乳腺组织样本中,共检测到 6388 个蛋白质,其假发现率 (FDR) p 值为 0.1,P 值为 -4。DCTN3和DDX6都与乳腺癌风险的降低有关,P值分别为1.01 × 10-3和3.25 × 10-4。其余两种蛋白质 LSP1 和 DNAJA3 的相应基因位于先前 GWAS 确定的乳腺癌风险位点上。在对 GWAS 确定的风险变异进行调整后,DNAJA3 的相关性仍然显著(p 值为 9.15 × 10-5,调整后的 p 值为 1.94 × 10-4)。然而,LSP1 的显著性变弱,p 值为 0.62。按乳腺癌亚型进行的分层分析发现,SMARCC1、LSP1 和 NCKAP1L 这三种蛋白质与管腔 A 型、管腔 B 型和 ER 阳性乳腺癌有关。NCKAP1L与GWAS确定的乳腺癌风险变异至少相距1Mb。在对 GWAS 确定的乳腺癌风险变异进行调整后,蛋白质 LSP1 的相关性仍然显著(对于管腔 B 亚型,调整后的 p 值为 6.43 × 10-3):我们首次进行了基于乳腺组织的PWAS,发现了7种与乳腺癌相关的蛋白质,包括5种以前未涉及的蛋白质。这些发现有助于我们更好地了解乳腺癌发生的潜在遗传机制。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

British Journal of Cancer
医学-肿瘤学
CiteScore
15.10
自引率
1.10%
发文量
383
审稿时长
6 months
期刊介绍:
The British Journal of Cancer is one of the most-cited general cancer journals, publishing significant advances in translational and clinical cancer research.It also publishes high-quality reviews and thought-provoking comment on all aspects of cancer prevention,diagnosis and treatment.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


