{"title":"Behavioral Nudging With Generative AI for Content Development in SMS Health Care Interventions: Case Study.","authors":"Rachel M Harrison, Ekaterina Lapteva, Anton Bibin","doi":"10.2196/52974","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Brief message interventions have demonstrated immense promise in health care, yet the development of these messages has suffered from a dearth of transparency and a scarcity of publicly accessible data sets. Moreover, the researcher-driven content creation process has raised resource allocation issues, necessitating a more efficient and transparent approach to content development.</p><p><strong>Objective: </strong>This research sets out to address the challenges of content development for SMS interventions by showcasing the use of generative artificial intelligence (AI) as a tool for content creation, transparently explaining the prompt design and content generation process, and providing the largest publicly available data set of brief messages and source code for future replication of our process.</p><p><strong>Methods: </strong>Leveraging the pretrained large language model GPT-3.5 (OpenAI), we generate a collection of messages in the context of medication adherence for individuals with type 2 diabetes using evidence-derived behavior change techniques identified in a prior systematic review. We create an attributed prompt designed to adhere to content (readability and tone) and SMS (character count and encoder type) standards while encouraging message variability to reflect differences in behavior change techniques.</p><p><strong>Results: </strong>We deliver the most extensive repository of brief messages for a singular health care intervention and the first library of messages crafted with generative AI. In total, our method yields a data set comprising 1150 messages, with 89.91% (n=1034) meeting character length requirements and 80.7% (n=928) meeting readability requirements. Furthermore, our analysis reveals that all messages exhibit diversity comparable to an existing publicly available data set created under the same theoretical framework for a similar setting.</p><p><strong>Conclusions: </strong>This research provides a novel approach to content creation for health care interventions using state-of-the-art generative AI tools. Future research is needed to assess the generated content for ethical, safety, and research standards, as well as to determine whether the intervention is successful in improving the target behaviors.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"3 ","pages":"e52974"},"PeriodicalIF":2.0000,"publicationDate":"2024-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11522651/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/52974","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Brief message interventions have demonstrated immense promise in health care, yet the development of these messages has suffered from a dearth of transparency and a scarcity of publicly accessible data sets. Moreover, the researcher-driven content creation process has raised resource allocation issues, necessitating a more efficient and transparent approach to content development.
Objective: This research sets out to address the challenges of content development for SMS interventions by showcasing the use of generative artificial intelligence (AI) as a tool for content creation, transparently explaining the prompt design and content generation process, and providing the largest publicly available data set of brief messages and source code for future replication of our process.
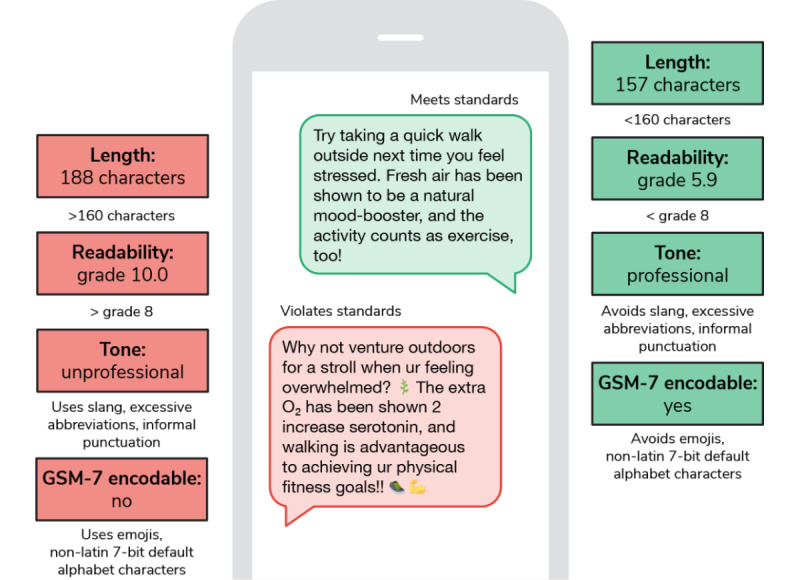
Methods: Leveraging the pretrained large language model GPT-3.5 (OpenAI), we generate a collection of messages in the context of medication adherence for individuals with type 2 diabetes using evidence-derived behavior change techniques identified in a prior systematic review. We create an attributed prompt designed to adhere to content (readability and tone) and SMS (character count and encoder type) standards while encouraging message variability to reflect differences in behavior change techniques.
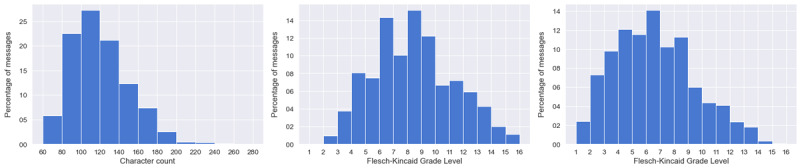
Results: We deliver the most extensive repository of brief messages for a singular health care intervention and the first library of messages crafted with generative AI. In total, our method yields a data set comprising 1150 messages, with 89.91% (n=1034) meeting character length requirements and 80.7% (n=928) meeting readability requirements. Furthermore, our analysis reveals that all messages exhibit diversity comparable to an existing publicly available data set created under the same theoretical framework for a similar setting.
Conclusions: This research provides a novel approach to content creation for health care interventions using state-of-the-art generative AI tools. Future research is needed to assess the generated content for ethical, safety, and research standards, as well as to determine whether the intervention is successful in improving the target behaviors.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


