Knowledge abstraction and filtering based federated learning over heterogeneous data views in healthcare
IF 12.4
1区 医学
Q1 HEALTH CARE SCIENCES & SERVICES
引用次数: 0
Abstract
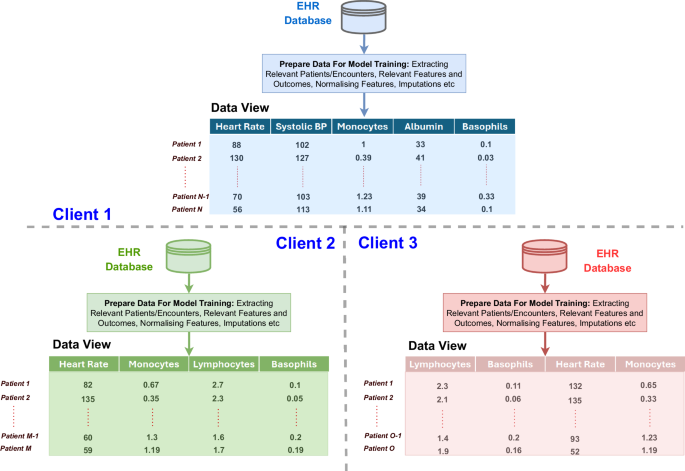
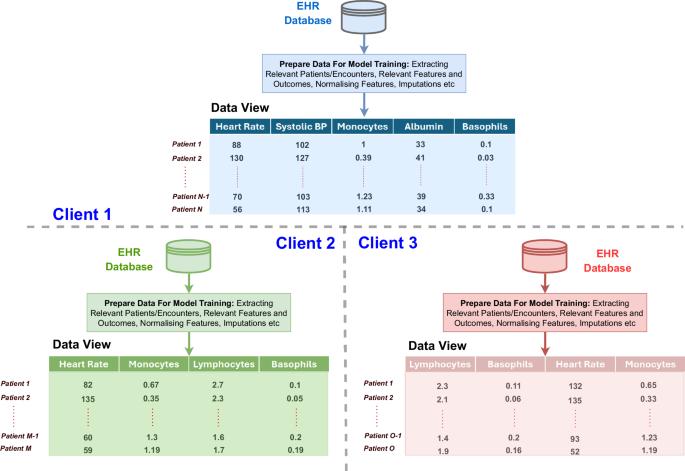
Robust data privacy regulations hinder the exchange of healthcare data among institutions, crucial for global insights and developing generalised clinical models. Federated learning (FL) is ideal for training global models using datasets from different institutions without compromising privacy. However, disparities in electronic healthcare records (EHRs) lead to inconsistencies in ML-ready data views, making FL challenging without extensive preprocessing and information loss. These differences arise from variations in services, care standards, and record-keeping practices. This paper addresses data view heterogeneity by introducing a knowledge abstraction and filtering-based FL framework that allows FL over heterogeneous data views without manual alignment or information loss. The knowledge abstraction and filtering mechanism maps raw input representations to a unified, semantically rich shared space for effective global model training. Experiments on three healthcare datasets demonstrate the framework’s effectiveness in overcoming data view heterogeneity and facilitating information sharing in a federated setup.
基于知识抽象和过滤的医疗保健领域异构数据视图联合学习
严格的数据隐私法规阻碍了医疗机构之间的数据交换,而数据交换对于了解全球情况和开发通用临床模型至关重要。联盟学习(FL)是在不损害隐私的情况下使用来自不同机构的数据集训练全球模型的理想选择。然而,电子医疗记录(EHR)的差异导致了 ML 就绪数据视图的不一致性,使得联合学习在没有大量预处理和信息丢失的情况下具有挑战性。这些差异源于服务、护理标准和记录保存实践的不同。本文通过引入基于知识抽象和过滤的 FL 框架来解决数据视图异构问题,该框架允许在异构数据视图上进行 FL,而无需手动调整或信息丢失。知识抽象和过滤机制将原始输入表征映射到统一的、语义丰富的共享空间,从而实现有效的全局模型训练。在三个医疗数据集上的实验证明了该框架在克服数据视图异构性和促进联合设置中的信息共享方面的有效性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

NPJ Digital Medicine
Multiple-
CiteScore
25.10
自引率
3.30%
发文量
170
审稿时长
15 weeks
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


