Muhammad Azam, Yibo Chen, Micheal Olaolu Arowolo, Haowang Liu, Mihail Popescu, Dong Xu
{"title":"A comprehensive evaluation of large language models in mining gene relations and pathway knowledge.","authors":"Muhammad Azam, Yibo Chen, Micheal Olaolu Arowolo, Haowang Liu, Mihail Popescu, Dong Xu","doi":"10.1002/qub2.57","DOIUrl":null,"url":null,"abstract":"<p><p>Understanding complex biological pathways, including gene-gene interactions and gene regulatory networks, is critical for exploring disease mechanisms and drug development. Manual literature curation of biological pathways cannot keep up with the exponential growth of new discoveries in the literature. Large-scale language models (LLMs) trained on extensive text corpora contain rich biological information, and they can be mined as a biological knowledge graph. This study assesses 21 LLMs, including both application programming interface (API)-based models and open-source models in their capacities of retrieving biological knowledge. The evaluation focuses on predicting gene regulatory relations (activation, inhibition, and phosphorylation) and the Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway components. Results indicated a significant disparity in model performance. API-based models GPT-4 and Claude-Pro showed superior performance, with an F1 score of 0.4448 and 0.4386 for the gene regulatory relation prediction, and a Jaccard similarity index of 0.2778 and 0.2657 for the KEGG pathway prediction, respectively. Open-source models lagged behind their API-based counterparts, whereas Falcon-180b and llama2-7b had the highest F1 scores of 0.2787 and 0.1923 in gene regulatory relations, respectively. The KEGG pathway recognition had a Jaccard similarity index of 0.2237 for Falcon-180b and 0.2207 for llama2-7b. Our study suggests that LLMs are informative in gene network analysis and pathway mapping, but their effectiveness varies, necessitating careful model selection. This work also provides a case study and insight into using LLMs das knowledge graphs. Our code is publicly available at the website of GitHub (Muh-aza).</p>","PeriodicalId":45660,"journal":{"name":"Quantitative Biology","volume":"12 4","pages":"360-374"},"PeriodicalIF":1.4000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11446478/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Quantitative Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1002/qub2.57","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/21 0:00:00","PubModel":"Epub","JCR":"Q4","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
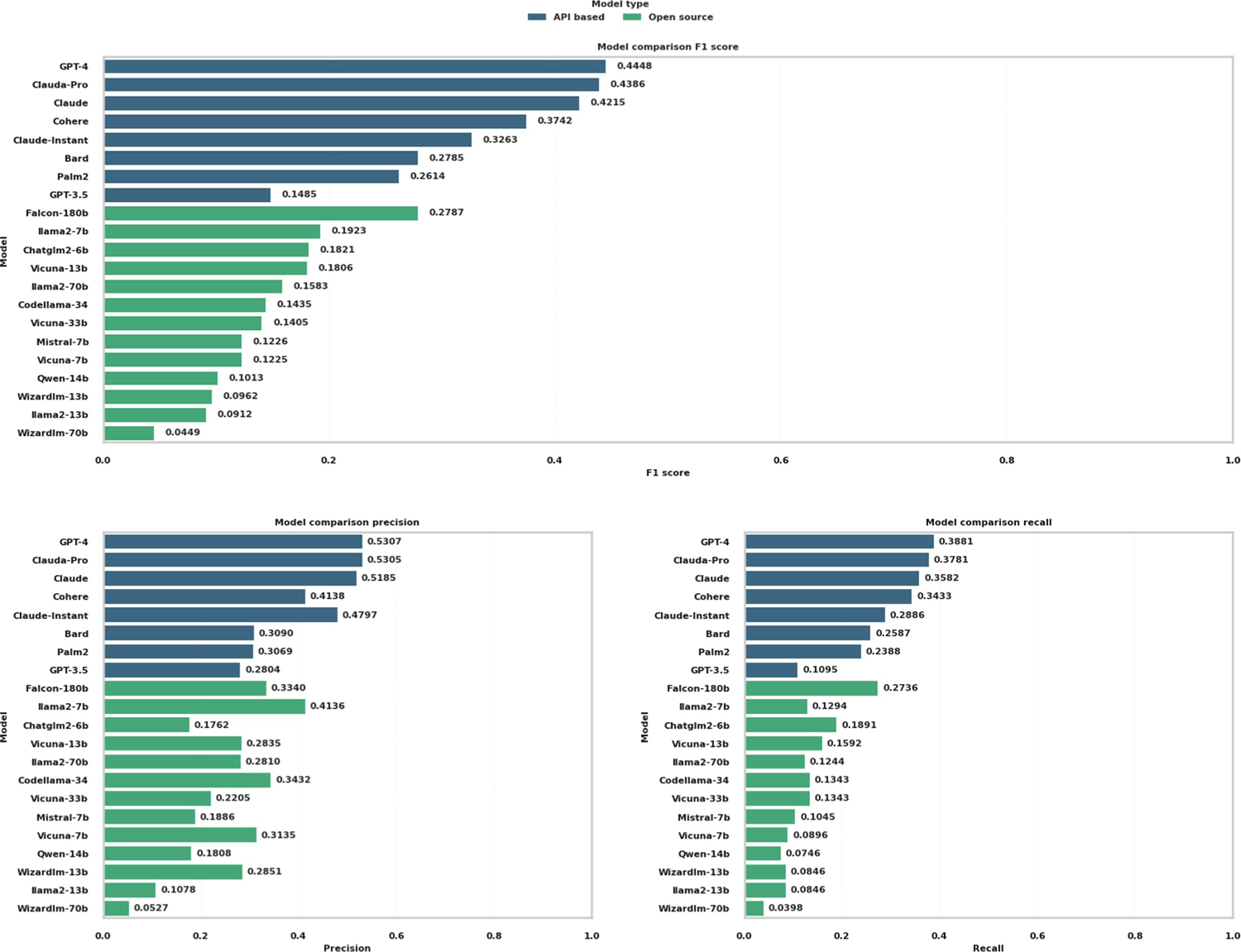
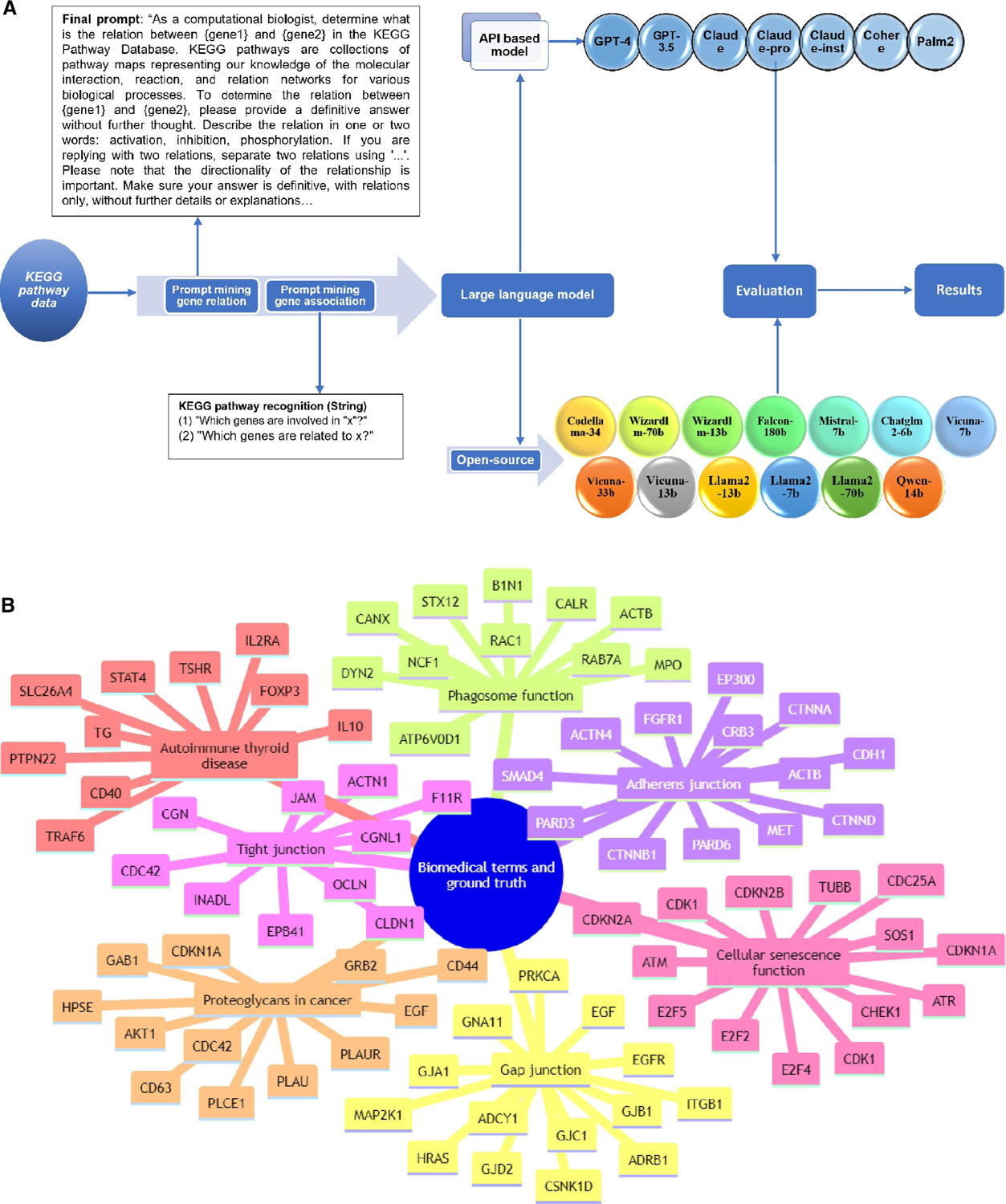
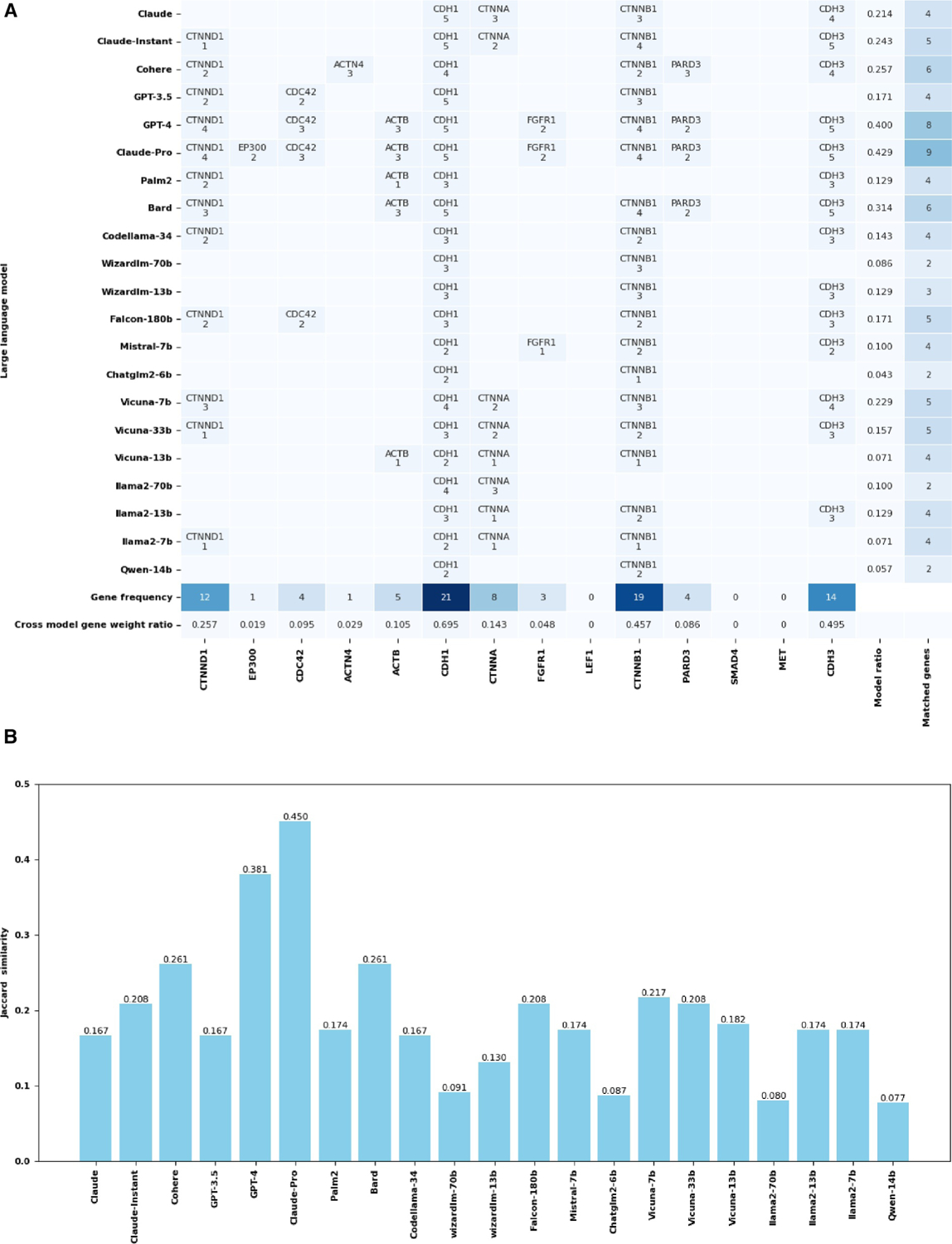
Understanding complex biological pathways, including gene-gene interactions and gene regulatory networks, is critical for exploring disease mechanisms and drug development. Manual literature curation of biological pathways cannot keep up with the exponential growth of new discoveries in the literature. Large-scale language models (LLMs) trained on extensive text corpora contain rich biological information, and they can be mined as a biological knowledge graph. This study assesses 21 LLMs, including both application programming interface (API)-based models and open-source models in their capacities of retrieving biological knowledge. The evaluation focuses on predicting gene regulatory relations (activation, inhibition, and phosphorylation) and the Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway components. Results indicated a significant disparity in model performance. API-based models GPT-4 and Claude-Pro showed superior performance, with an F1 score of 0.4448 and 0.4386 for the gene regulatory relation prediction, and a Jaccard similarity index of 0.2778 and 0.2657 for the KEGG pathway prediction, respectively. Open-source models lagged behind their API-based counterparts, whereas Falcon-180b and llama2-7b had the highest F1 scores of 0.2787 and 0.1923 in gene regulatory relations, respectively. The KEGG pathway recognition had a Jaccard similarity index of 0.2237 for Falcon-180b and 0.2207 for llama2-7b. Our study suggests that LLMs are informative in gene network analysis and pathway mapping, but their effectiveness varies, necessitating careful model selection. This work also provides a case study and insight into using LLMs das knowledge graphs. Our code is publicly available at the website of GitHub (Muh-aza).
期刊介绍:
Quantitative Biology is an interdisciplinary journal that focuses on original research that uses quantitative approaches and technologies to analyze and integrate biological systems, construct and model engineered life systems, and gain a deeper understanding of the life sciences. It aims to provide a platform for not only the analysis but also the integration and construction of biological systems. It is a quarterly journal seeking to provide an inter- and multi-disciplinary forum for a broad blend of peer-reviewed academic papers in order to promote rapid communication and exchange between scientists in the East and the West. The content of Quantitative Biology will mainly focus on the two broad and related areas: ·bioinformatics and computational biology, which focuses on dealing with information technologies and computational methodologies that can efficiently and accurately manipulate –omics data and transform molecular information into biological knowledge. ·systems and synthetic biology, which focuses on complex interactions in biological systems and the emergent functional properties, and on the design and construction of new biological functions and systems. Its goal is to reflect the significant advances made in quantitatively investigating and modeling both natural and engineered life systems at the molecular and higher levels. The journal particularly encourages original papers that link novel theory with cutting-edge experiments, especially in the newly emerging and multi-disciplinary areas of research. The journal also welcomes high-quality reviews and perspective articles.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


