{"title":"Navigating pathways to automated personality prediction: a comparative study of small and medium language models.","authors":"Fatima Habib, Zeeshan Ali, Akbar Azam, Komal Kamran, Fahad Mansoor Pasha","doi":"10.3389/fdata.2024.1387325","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Recent advancements in Natural Language Processing (NLP) and widely available social media data have made it possible to predict human personalities in various computational applications. In this context, pre-trained Large Language Models (LLMs) have gained recognition for their exceptional performance in NLP benchmarks. However, these models require substantial computational resources, escalating their carbon and water footprint. Consequently, a shift toward more computationally efficient smaller models is observed.</p><p><strong>Methods: </strong>This study compares a small model ALBERT (11.8M parameters) with a larger model, RoBERTa (125M parameters) in predicting big five personality traits. It utilizes the PANDORA dataset comprising Reddit comments, processing them on a Tesla P100-PCIE-16GB GPU. The study customized both models to support multi-output regression and added two linear layers for fine-grained regression analysis.</p><p><strong>Results: </strong>Results are evaluated on Mean Squared Error (MSE) and Root Mean Squared Error (RMSE), considering the computational resources consumed during training. While ALBERT consumed lower levels of system memory with lower heat emission, it took higher computation time compared to RoBERTa. The study produced comparable levels of MSE, RMSE, and training loss reduction.</p><p><strong>Discussion: </strong>This highlights the influence of training data quality on the model's performance, outweighing the significance of model size. Theoretical and practical implications are also discussed.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"7 ","pages":"1387325"},"PeriodicalIF":2.4000,"publicationDate":"2024-09-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11427259/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2024.1387325","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Recent advancements in Natural Language Processing (NLP) and widely available social media data have made it possible to predict human personalities in various computational applications. In this context, pre-trained Large Language Models (LLMs) have gained recognition for their exceptional performance in NLP benchmarks. However, these models require substantial computational resources, escalating their carbon and water footprint. Consequently, a shift toward more computationally efficient smaller models is observed.
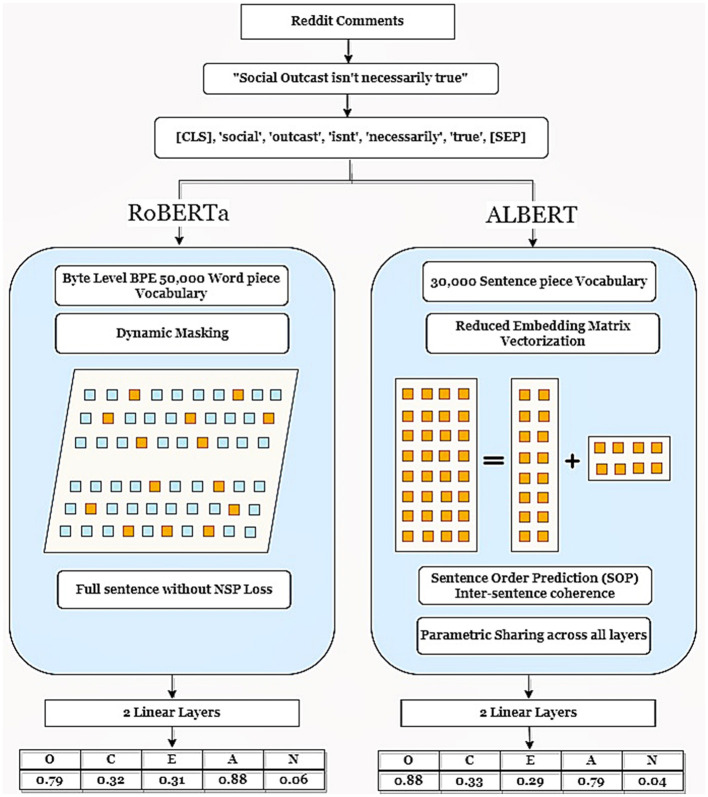
Methods: This study compares a small model ALBERT (11.8M parameters) with a larger model, RoBERTa (125M parameters) in predicting big five personality traits. It utilizes the PANDORA dataset comprising Reddit comments, processing them on a Tesla P100-PCIE-16GB GPU. The study customized both models to support multi-output regression and added two linear layers for fine-grained regression analysis.
Results: Results are evaluated on Mean Squared Error (MSE) and Root Mean Squared Error (RMSE), considering the computational resources consumed during training. While ALBERT consumed lower levels of system memory with lower heat emission, it took higher computation time compared to RoBERTa. The study produced comparable levels of MSE, RMSE, and training loss reduction.
Discussion: This highlights the influence of training data quality on the model's performance, outweighing the significance of model size. Theoretical and practical implications are also discussed.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


