Generating knowledge graphs through text mining of catalysis research related literature†
IF 4.4
3区 化学
Q2 CHEMISTRY, PHYSICAL
引用次数: 0
Abstract
Structured research data management in catalysis is crucial, especially for large amounts of data, and should be guided by FAIR principles for easy access and compatibility of data. Ontologies help to organize knowledge in a structured and FAIR way. The increasing numbers of scientific publications call for automated methods to preselect and access the desired knowledge while minimizing the effort to search for relevant publications. While ontology learning can be used to create structured knowledge graphs, named entity recognition allows detection and categorization of important information in text. This work combines ontology learning and named entity recognition for automated extraction of key data from publications and organization of the implicit knowledge in a machine- and user-readable knowledge graph and data. CatalysisIE is a pre-trained model for such information extraction for catalysis research. This model is used and extended in this work based on a new data set, increasing the precision and recall of the model with regard to the data set. Validation of the presented workflow is presented on two datasets regarding catalysis research. Preformulated SPARQL-queries are provided to show the usability and applicability of the resulting knowledge graph for researchers.
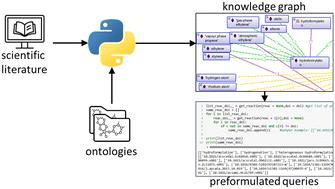
通过对催化研究相关文献的文本挖掘生成知识图谱†。
催化领域的结构化研究数据管理至关重要,尤其是对于大量数据而言,并且应遵循 FAIR 原则,以便于数据的访问和兼容性。本体论有助于以结构化和 FAIR 的方式组织知识。随着科学出版物数量的不断增加,需要采用自动化方法来预选和访问所需的知识,同时尽量减少搜索相关出版物的工作量。本体学习可用于创建结构化的知识图谱,而命名实体识别则可以检测文本中的重要信息并对其进行分类。这项工作结合了本体学习和命名实体识别,可自动从出版物中提取关键数据,并在机器和用户可读的知识图谱和数据中组织隐含知识。CatalysisIE 是一个预先训练好的模型,用于催化研究的信息提取。本工作基于新的数据集使用并扩展了这一模型,提高了模型在数据集方面的精确度和召回率。在两个有关催化研究的数据集上对所介绍的工作流程进行了验证。提供了预制的 SPARQL 查询,以显示所生成的知识图谱对研究人员的可用性和适用性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Catalysis Science & Technology
CHEMISTRY, PHYSICAL-
CiteScore
8.70
自引率
6.00%
发文量
587
审稿时长
1.5 months
期刊介绍:
A multidisciplinary journal focusing on cutting edge research across all fundamental science and technological aspects of catalysis.
Editor-in-chief: Bert Weckhuysen
Impact factor: 5.0
Time to first decision (peer reviewed only): 31 days
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


