{"title":"Effective knowledge representation and utilization for sustainable collaborative learning across heterogeneous systems","authors":"Trong Nghia Hoang","doi":"10.1002/aaai.12193","DOIUrl":null,"url":null,"abstract":"<p>The increasingly decentralized and private nature of data in our digital society has motivated the development of collaborative intelligent systems that enable knowledge aggregation among data owners. However, collaborative learning has only been investigated in simple settings. For example, clients are often assumed to train solution models <i>de novo</i>, disregarding all prior expertise. The learned model is typically represented in task-specific forms that are not generalizable to unseen, emerging scenarios. Finally, a universal model representation is enforced among collaborators, ignoring their local compute constraints or input representations. These limitations hampers the practicality of prior collaborative systems in learning scenarios with limited task data that demand constant knowledge adaptation and transfer across information silos, tasks, and learning models, as well as the utilization of prior solution expertise. Furthermore, prior collaborative learning frameworks are not sustainable on a macro scale where participants desire fairness allocation of benefits (e.g., access to the combined model) based on their costs of participation (e.g., overhead of model sharing and training synchronization, risk of information breaches, etc.). This necessitates a new perspective of collaborative learning where the server not only aggregates but also conducts valuation of the participant's contribution, and distribute aggregated information to individuals in commensurate to their contribution. To substantiate the above vision, we propose a new research agenda on developing effective and sustainable collaborative learning frameworks across heterogeneous systems, featuring three novel computational capabilities on knowledge organization: model expression, comprehension, and valuation.</p>","PeriodicalId":7854,"journal":{"name":"Ai Magazine","volume":"45 3","pages":"404-410"},"PeriodicalIF":3.2000,"publicationDate":"2024-09-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aaai.12193","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Ai Magazine","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/aaai.12193","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
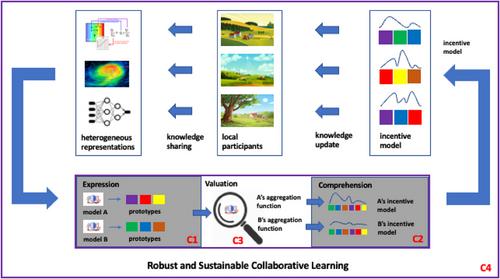
The increasingly decentralized and private nature of data in our digital society has motivated the development of collaborative intelligent systems that enable knowledge aggregation among data owners. However, collaborative learning has only been investigated in simple settings. For example, clients are often assumed to train solution models de novo, disregarding all prior expertise. The learned model is typically represented in task-specific forms that are not generalizable to unseen, emerging scenarios. Finally, a universal model representation is enforced among collaborators, ignoring their local compute constraints or input representations. These limitations hampers the practicality of prior collaborative systems in learning scenarios with limited task data that demand constant knowledge adaptation and transfer across information silos, tasks, and learning models, as well as the utilization of prior solution expertise. Furthermore, prior collaborative learning frameworks are not sustainable on a macro scale where participants desire fairness allocation of benefits (e.g., access to the combined model) based on their costs of participation (e.g., overhead of model sharing and training synchronization, risk of information breaches, etc.). This necessitates a new perspective of collaborative learning where the server not only aggregates but also conducts valuation of the participant's contribution, and distribute aggregated information to individuals in commensurate to their contribution. To substantiate the above vision, we propose a new research agenda on developing effective and sustainable collaborative learning frameworks across heterogeneous systems, featuring three novel computational capabilities on knowledge organization: model expression, comprehension, and valuation.
期刊介绍:
AI Magazine publishes original articles that are reasonably self-contained and aimed at a broad spectrum of the AI community. Technical content should be kept to a minimum. In general, the magazine does not publish articles that have been published elsewhere in whole or in part. The magazine welcomes the contribution of articles on the theory and practice of AI as well as general survey articles, tutorial articles on timely topics, conference or symposia or workshop reports, and timely columns on topics of interest to AI scientists.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


