DFCNet +: Cross-modal dynamic feature contrast net for continuous sign language recognition
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
In sign language communication, the combination of hand signs and facial expressions is used to convey messages in a fluid manner. Accurate interpretation relies heavily on understanding the context of these signs. Current methods, however, often focus on static images, missing the continuous flow and the story that unfolds through successive movements in sign language. To address this constraint, our research introduces the Dynamic Feature Contrast Net Plus (DFCNet +), a novel model that incorporates both dynamic feature extraction and cross-modal learning. The dynamic feature extraction module of DFCNet + uses dynamic trajectory capture to monitor and record motion across frames and apply key features as an enhancement tool that highlights pixels that are critical for recognizing important sign language movements, allowing the model to follow the temporal variation of the signs. In the cross-modal learning module, we depart from the conventional approach of aligning video frames with textual descriptions. Instead, we adopt a gloss-level alignment, which provides a more detailed match between the visual signals and their corresponding text glosses, capturing the intricate relationship between what is seen and the associated text. The enhanced proficiency of DFCNet + in discerning inter-frame details translates to heightened precision on benchmarks such as PHOENIX14, PHOENIX14-T and CSL-Daily. Such performance underscores its advantage in dynamic feature capture and inter-modal learning compared to conventional approaches to sign language interpretation. Our code is available at https://github.com/fyzjut/DFCNet_Plus.
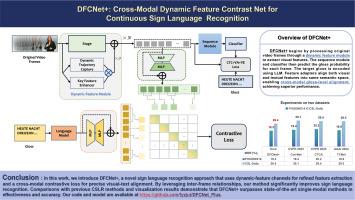
DFCNet +:用于连续手语识别的跨模态动态特征对比网
在手语交流中,手势和面部表情相结合,可以流畅地传递信息。准确的解释在很大程度上依赖于对这些手势语境的理解。然而,目前的方法通常只关注静态图像,而忽略了手语中通过连续动作展开的连续流和故事情节。为了解决这一制约因素,我们的研究引入了动态特征对比网(DFCNet Plus,DFCNet +),这是一种结合了动态特征提取和跨模态学习的新型模型。DFCNet + 的动态特征提取模块使用动态轨迹捕捉来监控和记录各帧的运动,并应用关键特征作为增强工具,突出识别重要手语动作的关键像素,使模型能够跟踪手语的时间变化。在跨模态学习模块中,我们摒弃了将视频帧与文本描述对齐的传统方法。相反,我们采用了词汇层面的对齐方式,在视觉信号和相应的文本词汇之间进行更详细的匹配,从而捕捉所见内容和相关文本之间错综复杂的关系。DFCNet + 在辨别帧间细节方面的能力得到了增强,从而提高了在 PHOENIX14、PHOENIX14-T 和 CSL-Daily 等基准测试中的精度。与传统的手语翻译方法相比,这种性能突出了它在动态特征捕捉和跨模态学习方面的优势。我们的代码见 https://github.com/fyzjut/DFCNet_Plus。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


