A learnable motion preserving pooling for action recognition
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Using deep neural networks (DNN) for video understanding tasks is expensive in terms of computation cost. Pooling layers in DNN which are widely used in most vision tasks to resize the spatial dimensions play crucial roles in reducing the computation and memory cost. In video-related tasks, pooling layers are also applied, mostly in the spatial dimension only as the standard average pooling in the temporal domain can significantly reduce its performance. This is because conventional temporal pooling degrades the underlying important motion features in consecutive frames. Such a phenomenon is rarely investigated and most state-of-art methods simply do not adopt temporal pooling, leading to enormous computation costs. In this work, we propose a learnable motion-preserving pooling (MPPool) layer that is able to preserve the general motion progression after the pooling. This pooling layer first locates the frames with the strongest motion features and then keeps these crucial features during pooling. Our experiments demonstrate that MPPool not only reduces the computation cost for video data modeling, but also increases the final prediction accuracy on various motion-centric and appearance-centric datasets.
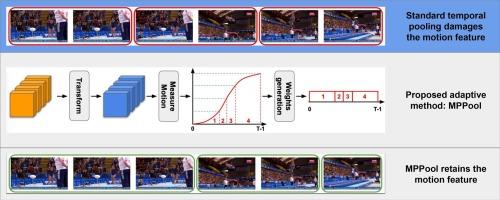
用于动作识别的可学习运动保护池
使用深度神经网络(DNN)执行视频理解任务的计算成本很高。深度神经网络中的池化层被广泛应用于大多数视觉任务中,用于调整空间维度的大小,在降低计算和内存成本方面发挥着至关重要的作用。在与视频相关的任务中,池化层也会被应用,但大多只应用于空间维度,因为时域的标准平均池化会大大降低其性能。这是因为传统的时域池化会降低连续帧中潜在的重要运动特征。这种现象很少被研究,大多数最先进的方法根本不采用时域池化,从而导致巨大的计算成本。在这项工作中,我们提出了一种可学习的运动保留池化(MPPool)层,能够在池化后保留一般的运动进展。这个池化层首先定位具有最强运动特征的帧,然后在池化过程中保留这些关键特征。我们的实验证明,MPPool 不仅降低了视频数据建模的计算成本,还提高了各种以运动为中心和以外观为中心的数据集的最终预测准确率。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


