{"title":"Video-driven musical composition using large language model with memory-augmented state space","authors":"Wan-He Kai, Kai-Xin Xing","doi":"10.1007/s00371-024-03606-w","DOIUrl":null,"url":null,"abstract":"<p>The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. However, the research work on LLms for music inspiration is still in its infancy. To fill the gap in this field and break through the dilemma that LLMs can only understand short videos with limited frames, we propose a large language model with state space for long-term video-to-music generation. To capture long-range dependency and maintaining high performance, while further decrease the computing cost, our overall network includes the Enhanced Video Mamba, which incorporates continuous moving window partitioning and local feature augmentation, and a long-term memory bank that captures and aggregates historical video information to mitigate information loss in long sequences. This framework achieves both subquadratic-time computation and near-linear memory complexity, enabling effective long-term video-to-music generation. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models. Our code released on https://github.com/kai211233/S2L2-V2M.</p>","PeriodicalId":501186,"journal":{"name":"The Visual Computer","volume":"26 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Visual Computer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00371-024-03606-w","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
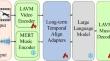
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. However, the research work on LLms for music inspiration is still in its infancy. To fill the gap in this field and break through the dilemma that LLMs can only understand short videos with limited frames, we propose a large language model with state space for long-term video-to-music generation. To capture long-range dependency and maintaining high performance, while further decrease the computing cost, our overall network includes the Enhanced Video Mamba, which incorporates continuous moving window partitioning and local feature augmentation, and a long-term memory bank that captures and aggregates historical video information to mitigate information loss in long sequences. This framework achieves both subquadratic-time computation and near-linear memory complexity, enabling effective long-term video-to-music generation. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models. Our code released on https://github.com/kai211233/S2L2-V2M.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:



