{"title":"RBCA-ETS: enhancing extractive text summarization with contextual embedding and word-level attention","authors":"Ravindra Gangundi, Rajeswari Sridhar","doi":"10.1007/s41870-024-02192-3","DOIUrl":null,"url":null,"abstract":"<p>The existing limitations in extractive text summarization encompass challenges related to preserving contextual features, limited feature extraction capabilities, and handling hierarchical and compositional aspects. To address these issues, the RoBERTa-BiLSTM-CNN-Attention Extractive Text Summarization, i.e., the RBCA-ETS model, is proposed in this work. RoBERTa word embedding is used to generate contextual embeddings. Parallelly connected CNN and BiLSTM layers extract textual features. CNN focuses more on local features, and BiLSTM captures long-range dependencies that extend across sentences. These two feature sets are concatenated and forwarded to the attention layer, highlighting the most relevant features. In the output layer, a fully connected layer receives the attention vector and calculates sentence scores for each sentence. This leads to the generation of the final summary. The RBCA-ETS model has demonstrated superior performance on the CNN-Daily Mail (CNN/DM) dataset compared to many state-of-the-art methods, and it has also outperformed existing state-of-the-art techniques when tested on the out-of-domain DUC 2002 dataset.</p>","PeriodicalId":14138,"journal":{"name":"International Journal of Information Technology","volume":"20 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-09-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Information Technology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-024-02192-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
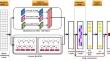
The existing limitations in extractive text summarization encompass challenges related to preserving contextual features, limited feature extraction capabilities, and handling hierarchical and compositional aspects. To address these issues, the RoBERTa-BiLSTM-CNN-Attention Extractive Text Summarization, i.e., the RBCA-ETS model, is proposed in this work. RoBERTa word embedding is used to generate contextual embeddings. Parallelly connected CNN and BiLSTM layers extract textual features. CNN focuses more on local features, and BiLSTM captures long-range dependencies that extend across sentences. These two feature sets are concatenated and forwarded to the attention layer, highlighting the most relevant features. In the output layer, a fully connected layer receives the attention vector and calculates sentence scores for each sentence. This leads to the generation of the final summary. The RBCA-ETS model has demonstrated superior performance on the CNN-Daily Mail (CNN/DM) dataset compared to many state-of-the-art methods, and it has also outperformed existing state-of-the-art techniques when tested on the out-of-domain DUC 2002 dataset.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


