Language abnormalities in Alzheimer's disease indicate reduced informativeness
Abstract
Objective
This study aims to elucidate the cognitive underpinnings of language abnormalities in Alzheimer's Disease (AD) using a computational cross-linguistic approach and ultimately enhance the understanding and diagnostic accuracy of the disease.
Methods
Computational analyses were conducted on language samples of 156 English and 50 Persian speakers, comprising both AD patients and healthy controls, to extract language indicators of AD. Furthermore, we introduced a machine learning-based metric, Language Informativeness Index (LII), to quantify empty speech.
Results
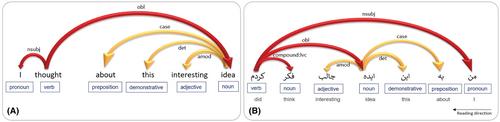
Despite considerable disparities in surface structures between the two languages, we observed consistency across language indicators of AD in both English and Persian. Notably, indicators of AD in English resulted in a classification accuracy of 90% in classifying AD in Persian. The substantial degree of transferability suggests that the language abnormalities of AD do not tightly link to the surface structures specific to English. Subsequently, we posited that these abnormalities stem from impairments in a more universal aspect of language production: the ability to generate informative messages independent of the language spoken. Consistent with this hypothesis, we found significant correlations between language indicators of AD and empty speech in both English and Persian.
Interpretation
The findings of this study suggest that language impairments in AD arise from a deficit in a universal aspect of message formation rather than from the breakdown of language-specific morphosyntactic structures. Beyond enhancing our understanding of the psycholinguistic deficits of AD, our approach fosters the development of diagnostic tools across various languages, enhancing health equity and biocultural diversity.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


