{"title":"A semantic approach for sarcasm identification for preventing fake news spreading on social networks","authors":"Fethi Fkih, Delel Rhouma, Hajar Alghofaily","doi":"10.1007/s41870-024-02156-7","DOIUrl":null,"url":null,"abstract":"<p>Misinterpreting satirical posts can contribute to the spread of misinformation and potentially be a source of what is commonly referred to as “fake news”. Satire is a form of humor that often involves exaggeration, irony, or ridicule to comment on or criticize a particular subject. While satirical content is not intended to be taken literally, there are instances where individuals may misinterpret it, leading to the dissemination of false information. In fact, we can reduce the spread of fake news by preventing people from misinterpreting satirical posts. However, sarcasm recognition is considered a challenging task in the Sentiment Analysis domain. Even for humans, it can be difficult to recognize irony and sarcasm, which conveys a sharp, bitter remark or criticism in ambiguous and unclear natural language. This makes the identification much more difficult for an automated model. In this paper, we have carried out an in-depth literature review about the main approaches used for sarcasm detection and especially those based on Machine Learning (ML) models. Then, a study was conducted with a series of binary classification models that exploit a variety of statistical and semantic features. Our experiments have been carried out on twitter dataset obtained from SemEval-2018 Task 3. An extensive evaluation of each set of classifiers demonstrates the efficiency of our proposed model in detecting and identifying sarcastic content in tweets. Finally, we compared the performance of machine learning models using our proposed features with our baseline and state-of-the-art on the same dataset. By using Support Vector Machine (SVM) model and the proposed features, we outperform the state-of-the-art and we obtained an accuracy of 79.46% with a F-score equal to 79.66% which considered a promising result in this field.</p>","PeriodicalId":14138,"journal":{"name":"International Journal of Information Technology","volume":"27 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-08-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Information Technology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-024-02156-7","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
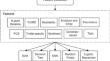
Abstract
Misinterpreting satirical posts can contribute to the spread of misinformation and potentially be a source of what is commonly referred to as “fake news”. Satire is a form of humor that often involves exaggeration, irony, or ridicule to comment on or criticize a particular subject. While satirical content is not intended to be taken literally, there are instances where individuals may misinterpret it, leading to the dissemination of false information. In fact, we can reduce the spread of fake news by preventing people from misinterpreting satirical posts. However, sarcasm recognition is considered a challenging task in the Sentiment Analysis domain. Even for humans, it can be difficult to recognize irony and sarcasm, which conveys a sharp, bitter remark or criticism in ambiguous and unclear natural language. This makes the identification much more difficult for an automated model. In this paper, we have carried out an in-depth literature review about the main approaches used for sarcasm detection and especially those based on Machine Learning (ML) models. Then, a study was conducted with a series of binary classification models that exploit a variety of statistical and semantic features. Our experiments have been carried out on twitter dataset obtained from SemEval-2018 Task 3. An extensive evaluation of each set of classifiers demonstrates the efficiency of our proposed model in detecting and identifying sarcastic content in tweets. Finally, we compared the performance of machine learning models using our proposed features with our baseline and state-of-the-art on the same dataset. By using Support Vector Machine (SVM) model and the proposed features, we outperform the state-of-the-art and we obtained an accuracy of 79.46% with a F-score equal to 79.66% which considered a promising result in this field.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


