{"title":"Combining Semi-supervised Clustering and Classification Under a Generalized Framework","authors":"Zhen Jiang, Lingyun Zhao, Yu Lu","doi":"10.1007/s00357-024-09489-9","DOIUrl":null,"url":null,"abstract":"<p>Most machine learning algorithms rely on having a sufficient amount of labeled data to train a reliable classifier. However, labeling data is often costly and time-consuming, while unlabeled data can be readily accessible. Therefore, learning from both labeled and unlabeled data has become a hot topic of interest. Inspired by the co-training algorithm, we present a learning framework called CSCC, which combines semi-supervised clustering and classification to learn from both labeled and unlabeled data. Unlike existing co-training style methods that construct diverse classifiers to learn from each other, CSCC leverages the diversity between semi-supervised clustering and classification models to achieve mutual enhancement. Existing classification algorithms can be easily adapted to CSCC, allowing them to generalize from a few labeled data. Especially, in order to bridge the gap between class information and clustering, we propose a semi-supervised hierarchical clustering algorithm that utilizes labeled data to guide the process of cluster-splitting. Within the CSCC framework, we introduce two loss functions to supervise the iterative updating of the semi-supervised clustering and classification models, respectively. Extensive experiments conducted on a variety of benchmark datasets validate the superiority of CSCC over other state-of-the-art methods.</p>","PeriodicalId":50241,"journal":{"name":"Journal of Classification","volume":"13 1","pages":""},"PeriodicalIF":1.9000,"publicationDate":"2024-08-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Classification","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00357-024-09489-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
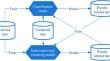
Most machine learning algorithms rely on having a sufficient amount of labeled data to train a reliable classifier. However, labeling data is often costly and time-consuming, while unlabeled data can be readily accessible. Therefore, learning from both labeled and unlabeled data has become a hot topic of interest. Inspired by the co-training algorithm, we present a learning framework called CSCC, which combines semi-supervised clustering and classification to learn from both labeled and unlabeled data. Unlike existing co-training style methods that construct diverse classifiers to learn from each other, CSCC leverages the diversity between semi-supervised clustering and classification models to achieve mutual enhancement. Existing classification algorithms can be easily adapted to CSCC, allowing them to generalize from a few labeled data. Especially, in order to bridge the gap between class information and clustering, we propose a semi-supervised hierarchical clustering algorithm that utilizes labeled data to guide the process of cluster-splitting. Within the CSCC framework, we introduce two loss functions to supervise the iterative updating of the semi-supervised clustering and classification models, respectively. Extensive experiments conducted on a variety of benchmark datasets validate the superiority of CSCC over other state-of-the-art methods.
期刊介绍:
To publish original and valuable papers in the field of classification, numerical taxonomy, multidimensional scaling and other ordination techniques, clustering, tree structures and other network models (with somewhat less emphasis on principal components analysis, factor analysis, and discriminant analysis), as well as associated models and algorithms for fitting them. Articles will support advances in methodology while demonstrating compelling substantive applications. Comprehensive review articles are also acceptable. Contributions will represent disciplines such as statistics, psychology, biology, information retrieval, anthropology, archeology, astronomy, business, chemistry, computer science, economics, engineering, geography, geology, linguistics, marketing, mathematics, medicine, political science, psychiatry, sociology, and soil science.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


