Michael L. Pennell, Matthew W. Wheeler, Scott S. Auerbach
{"title":"A hierarchical constrained density regression model for predicting cluster-level dose-response","authors":"Michael L. Pennell, Matthew W. Wheeler, Scott S. Auerbach","doi":"10.1002/env.2880","DOIUrl":null,"url":null,"abstract":"<p>With the advent of new alternative methods for rapid toxicity screening of chemicals comes the need for new statistical methodologies which appropriately synthesize the large amount of data collected. For example, transcriptomic assays can be used to assess the impact of a chemical on thousands of genes, but current approaches to analyzing the data treat each gene separately and do not allow sharing of information among genes within pathways. Furthermore, the methods employed are fully parametric and do not account for changes in distribution shape that may occur at high exposure levels. To address the limitations of these methods, we propose Constrained Logistic Density Regression (COLDER) to model expression data from different genes simultaneously. Under COLDER, the dose-response function for each gene is assigned a prior via a discrete logistic stick-breaking process (LSBP) whose weights depend on gene-level characteristics (e.g., pathway membership) and atoms consist of different dose-response functions subject to a shape constraint that ensures biological plausibility. The posterior distribution for the benchmark dose among genes within the same pathways can be estimated directly from the model, which is another advantage over current methods. The ability of COLDER to predict gene-level dose-response is evaluated in a simulation study and the method is illustrated with data from a National Toxicology Program study of Aflatoxin B1.</p>","PeriodicalId":50512,"journal":{"name":"Environmetrics","volume":"35 7","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2024-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/env.2880","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Environmetrics","FirstCategoryId":"93","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/env.2880","RegionNum":3,"RegionCategory":"环境科学与生态学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"ENVIRONMENTAL SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
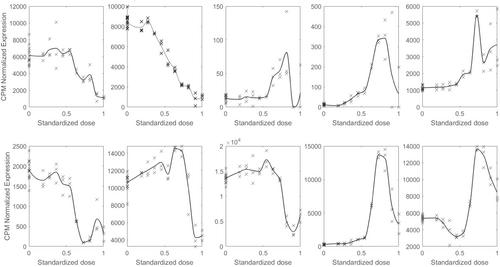
With the advent of new alternative methods for rapid toxicity screening of chemicals comes the need for new statistical methodologies which appropriately synthesize the large amount of data collected. For example, transcriptomic assays can be used to assess the impact of a chemical on thousands of genes, but current approaches to analyzing the data treat each gene separately and do not allow sharing of information among genes within pathways. Furthermore, the methods employed are fully parametric and do not account for changes in distribution shape that may occur at high exposure levels. To address the limitations of these methods, we propose Constrained Logistic Density Regression (COLDER) to model expression data from different genes simultaneously. Under COLDER, the dose-response function for each gene is assigned a prior via a discrete logistic stick-breaking process (LSBP) whose weights depend on gene-level characteristics (e.g., pathway membership) and atoms consist of different dose-response functions subject to a shape constraint that ensures biological plausibility. The posterior distribution for the benchmark dose among genes within the same pathways can be estimated directly from the model, which is another advantage over current methods. The ability of COLDER to predict gene-level dose-response is evaluated in a simulation study and the method is illustrated with data from a National Toxicology Program study of Aflatoxin B1.
期刊介绍:
Environmetrics, the official journal of The International Environmetrics Society (TIES), an Association of the International Statistical Institute, is devoted to the dissemination of high-quality quantitative research in the environmental sciences.
The journal welcomes pertinent and innovative submissions from quantitative disciplines developing new statistical and mathematical techniques, methods, and theories that solve modern environmental problems. Articles must proffer substantive, new statistical or mathematical advances to answer important scientific questions in the environmental sciences, or must develop novel or enhanced statistical methodology with clear applications to environmental science. New methods should be illustrated with recent environmental data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


