Lingfeng Gui, Alan Armstrong, Amparo Galindo, Fareed Bhasha Sayyed, Stanley P. Kolis and Claire S. Adjiman
{"title":"On the design of optimal computer experiments to model solvent effects on reaction kinetics†","authors":"Lingfeng Gui, Alan Armstrong, Amparo Galindo, Fareed Bhasha Sayyed, Stanley P. Kolis and Claire S. Adjiman","doi":"10.1039/D4ME00074A","DOIUrl":null,"url":null,"abstract":"<p >Developing an accurate predictive model of solvent effects on reaction kinetics is a challenging task, yet it can play an important role in process development. While first-principles or machine learning models are often compute- or data-intensive, simple surrogate models, such as multivariate linear or quadratic regression models, are useful when computational resources and data are scarce. The judicious choice of a small set of training data, <em>i.e.</em>, a set of solvents in which quantum mechanical (QM) calculations of liquid-phase rate constants are to be performed, is critical to obtaining a reliable model. This is, however, made especially challenging by the highly irregular shape of the discrete space of possible experiments (solvent choices). In this work, we demonstrate that when choosing a set of computer experiments to generate training data, the D-optimality criterion value of the chosen set correlates well with the likelihood of achieving good model performance. With the Menshutkin reaction of pyridine and phenacyl bromide as a case study, this finding is further verified <em>via</em> the evaluation of the surrogate models regressed using D-optimal solvent sets generated from four distinct selection spaces. We also find that incorporating quadratic terms in the surrogate model and choosing the D-optimal solvent set from a selection space similar to the test set can significantly improve the accuracy of reaction rate constant predictions while using a small training dataset. Our approach holds promise for the use of statistical optimality criteria for other types of computer experiments, supporting the construction of surrogate models with reduced resource and data requirements.</p>","PeriodicalId":91,"journal":{"name":"Molecular Systems Design & Engineering","volume":" 12","pages":" 1254-1274"},"PeriodicalIF":3.2000,"publicationDate":"2024-09-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/me/d4me00074a?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Systems Design & Engineering","FirstCategoryId":"5","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/me/d4me00074a","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
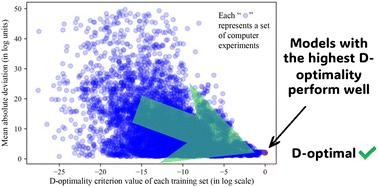
Developing an accurate predictive model of solvent effects on reaction kinetics is a challenging task, yet it can play an important role in process development. While first-principles or machine learning models are often compute- or data-intensive, simple surrogate models, such as multivariate linear or quadratic regression models, are useful when computational resources and data are scarce. The judicious choice of a small set of training data, i.e., a set of solvents in which quantum mechanical (QM) calculations of liquid-phase rate constants are to be performed, is critical to obtaining a reliable model. This is, however, made especially challenging by the highly irregular shape of the discrete space of possible experiments (solvent choices). In this work, we demonstrate that when choosing a set of computer experiments to generate training data, the D-optimality criterion value of the chosen set correlates well with the likelihood of achieving good model performance. With the Menshutkin reaction of pyridine and phenacyl bromide as a case study, this finding is further verified via the evaluation of the surrogate models regressed using D-optimal solvent sets generated from four distinct selection spaces. We also find that incorporating quadratic terms in the surrogate model and choosing the D-optimal solvent set from a selection space similar to the test set can significantly improve the accuracy of reaction rate constant predictions while using a small training dataset. Our approach holds promise for the use of statistical optimality criteria for other types of computer experiments, supporting the construction of surrogate models with reduced resource and data requirements.
期刊介绍:
Molecular Systems Design & Engineering provides a hub for cutting-edge research into how understanding of molecular properties, behaviour and interactions can be used to design and assemble better materials, systems, and processes to achieve specific functions. These may have applications of technological significance and help address global challenges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


